



.png.c9b8f3e9eda461da3c0e9ca5ff8c6888.png)
In Python crawlers, anti-crawler mechanisms will be encountered. If you need to access the normal browser, the content will be displayed, that is, the content will be loaded dynamically. I wrote earlier that using Selenium to implement it. But configuration is more troublesome. Therefore, another method is introduced here!
Use Python + playwright to implement anti-crawler. Since a higher version of Python environment uses pip to install related modules, an error will be reported. Therefore, it is recommended to use a virtual environment.
Selenium Crawler Reference Article 《Python+Selenium 反爬虫实战》
Create a virtual environment
python3 -m venv biiaoge #biaoge is the name of the virtual environment
source bolde/bin/activate #Activate virtual environment 
Next, we need to install relevant tools in the virtual environment.
Install playwright
pip3 install playwright 
After the installation is completed, install the corresponding browser (there is no browser in the local environment to install, if there is, you can ignore it)
playwright install firefox 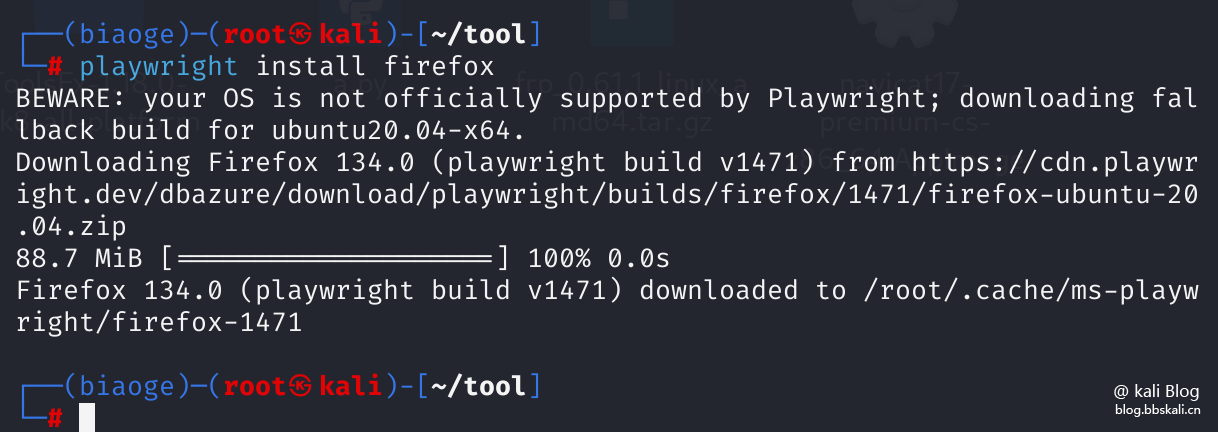
Because it is installed in a virtual environment, it has no impact on the local environment.
Sample code: from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
# Use sync_playwright context manager
with sync_playwright() as p:
# Start Firefox browser
browser=p.firefox.launch(headless=True)
# Create a new browser page
page=browser.new_page(
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
)
# Open the landing page
page.goto('https://data.xxxx.cn/easyquery.htm?cn=A01zb=A010G06sj=202502')
# Wait for the page to load
page.wait_for_load_state('networkidle')
# Get rendered HTML
html=page.content()
soup=BeautifulSoup(html, 'html.parser')
# Close the browser
browser.close()
# Analyze data
table_main=soup.find('table', id='table_main')
if table_main:
time_th=table_main.find_all('th')[1]
time=time_th.find('strong').get_text(strip=True)
tbody=table_main.find('tbody')
data=[]
for tr in tbody.find_all('tr'):
tds=tr.find_all('td')
indicator=tds[0].get_text(strip=True).replace('\n', '')
price=tds[1].get_text(strip=True)
data.append((time, indicator, price))
for item in data:
print(f'Time : {item[0]}')
print(f'index: {item[1]}')
print(f' price : {item[2]} yuan/kg\n')
else:
print('Table data not found')
Effect
Precautions
Every time you run a script, you need to go to the virtual environment. Therefore, it is best to recommend writing a script.