



.png.c9b8f3e9eda461da3c0e9ca5ff8c6888.png)
Scrapy is an application framework that is widely used in crawling websites and extracting structured data, such as data mining, information processing, etc. Its design is for website crawlers. It has developed to use APIs to extract data. It is a general website crawling tool.
Installation
In kali, because the python environment has been installed, we can directly install it with the following command.
pip install Scrapy 
Isn't the installation very easy?
Now we will demonstrate how to crawl through the official small demo.
Save the following file as a 22.py file
import scrapy
class QuotesSpider(scrapy.Spider):
name='quotes'
start_urls=[
'https://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'author': quote.xpath('span/small/text()').get(),
'text': quote.css('span.text:text').get(),
}
next_page=response.css('li.next a:attr('href')').get()
if next_page is not None:
yield response.follow(next_page, self.parse) execute the following command
scrapy runspider 22.py -o quotes.jl crawler results will be saved to quotes.jl file. Save data format as json.
Crawler results 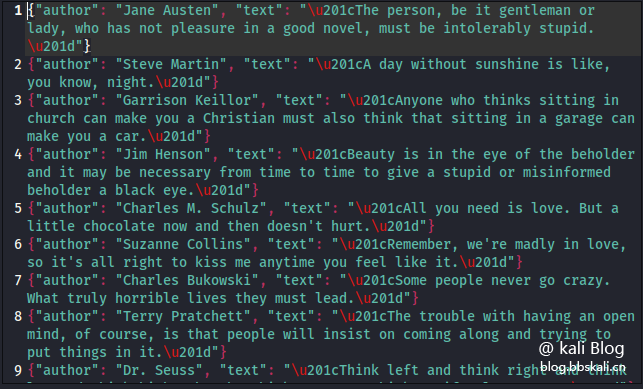
Code Analysis
Now we analyze the code
First, let’s take a look at the demo page provided by the official 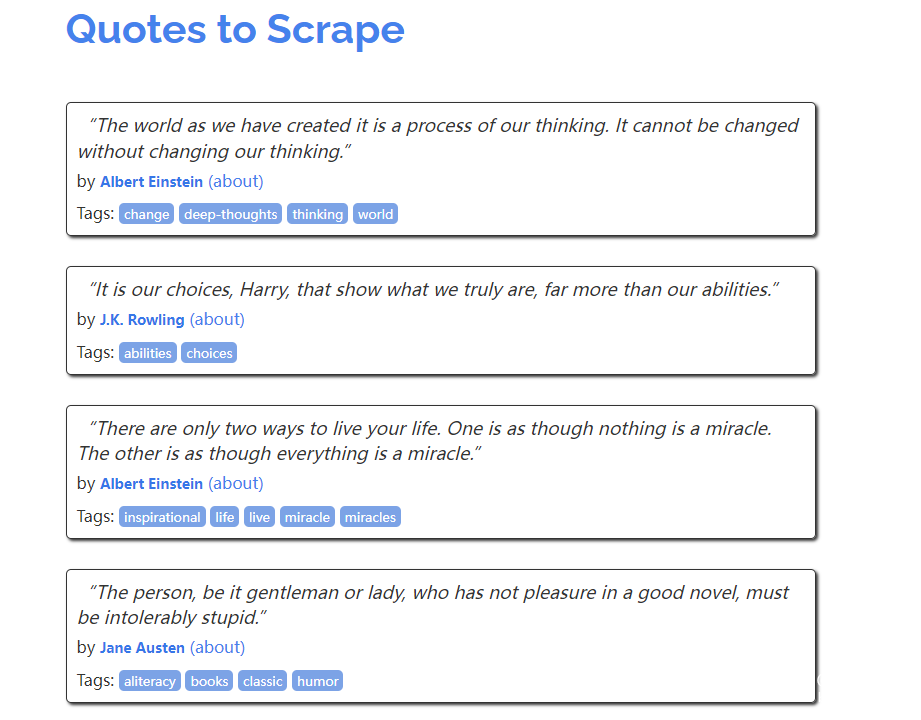
The code for this is as follows
div class='quote' itemscope='' itemtype='http://schema.org/CreativeWork'
span class='text' itemprop='text'"The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking."/span
spanby small class='author' itemprop='author'Albert Einstein/small
a href='/author/Albert-Einstein'(about)/a
/span
div class='tags'
Tags:
meta class='keywords' itemprop='keywords' content='change,deep-thoughts,thinking,world'
a class='tag' href='/tag/change/page/1/'change/a
a class='tag' href='/tag/deep-thoughts/page/1/'deep-thoughts/a
a class='tag' href='/tag/thinking/page/1/'thinking/a
a class='tag' href='/tag/world/page/1/'world/a
/div
/div Now we analyze the crawler code
#Import the crawler module
import scrapy
class QuotesSpider(scrapy.Spider):
#Define two variables name and start_urls. Among them, start_urls is the target website of the crawler.
name='quotes'
start_urls=[
'https://quotes.toscrape.com/',
]
def parse(self, response):
#Travel over elements that use css as quote
for quote in response.css('div.quote'):
# Generate a dictionary containing the extracted quote text and author
#Get the values of author and text under DIV
yield {
'author': quote.xpath('span/small/text()').get(),
'text': quote.css('span.text:text').get(),
}
#Find links to the next page
next_page=response.css('li.next a:attr('href')').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
quote.xpath('span/small/text()') Deep traversal to obtain the span tag under the target div, the small tag under the span tag, and pass in text (). Use the get() function to get its text value
The DIV is as follows
spanby small class='author' itemprop='author'Albert Einstein/smallquote.css('span.text:text').get(), get the value of the css under the span element under the css as the text element.
The DIV for this is as follows:
span class='text' itemprop='text'"The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking."/span Similarly, we can write out the value of the get tag tag.
div class='tags'
a class='tag' href='/tag/humor/page/1/'humor/a
/div'tags': quote.css('a.tag:text').getall() Here getall is to get all.
The slight test
Here we crawl the member rankings in the Big Cousin forum as an example
import scrapy
class QuotesSpider(scrapy.Spider):
name='quotes'
start_urls=[
'https://bbskali.cn/portal.php',
]
def parse(self, response):
for quote in response.css('div.z'):
yield {
'z': quote.xpath('p/a/text()').get(),
'z1': quote.css('p:text').get(),
}
next_page=response.css('li.next a:attr('href')').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
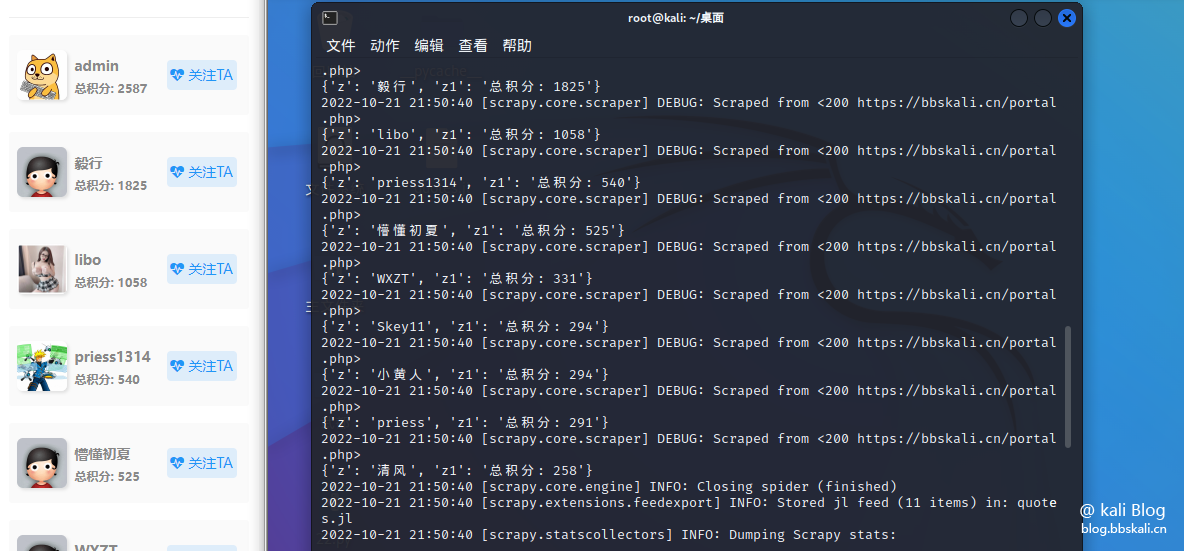
How about it, it’s simple!