



.png.c9b8f3e9eda461da3c0e9ca5ff8c6888.png)
In the previous article, we talked about using the web scraper browser plug-in to implement crawler. But my friend didn't understand, so we explained this article in depth. Hope it will be helpful to your study and work.
Single page information crawl
This is the most basic and simplest crawler. That is, all the desired information is on the same page and has not been paging. We just need to use web scraper to crawl directly. Example:
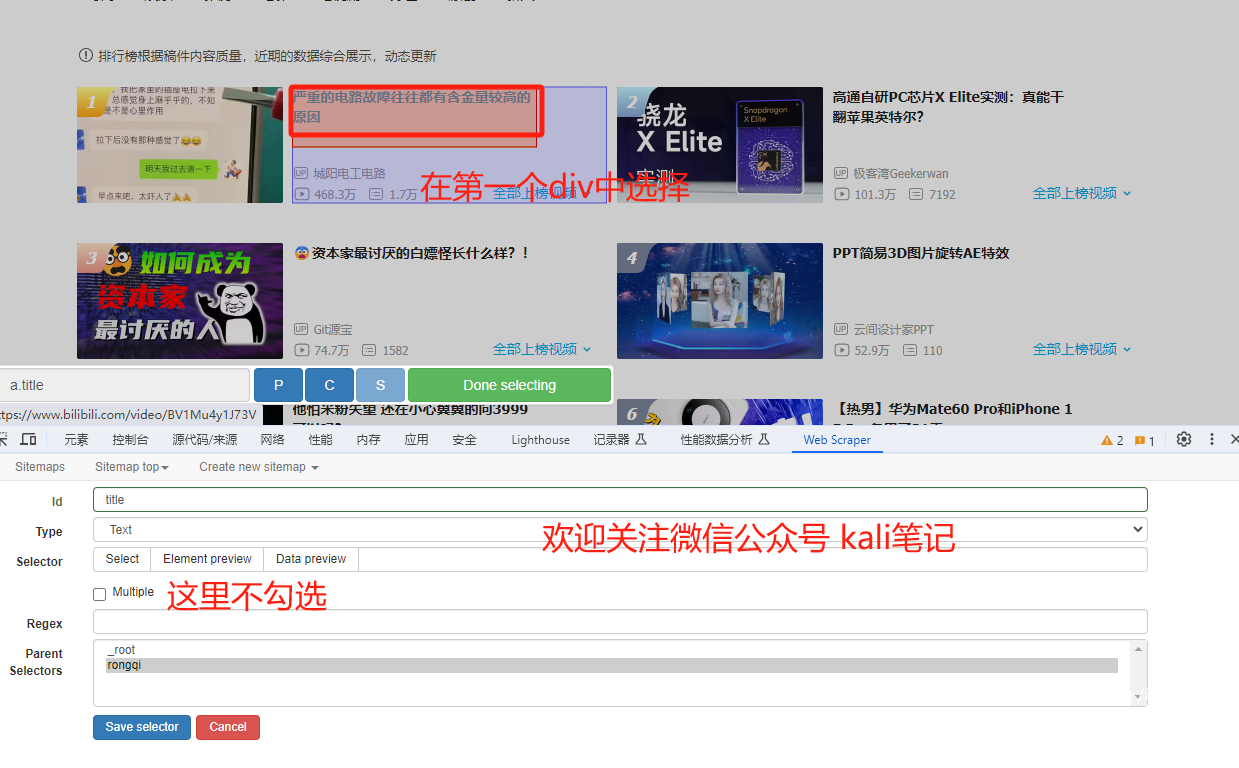
Crawl the data in the B station rankings, including video titles Author Playbacks Number of barrages 
Click Create new sitemap to create a crawler.
Next, click add new selector to create crawled content. Here I have created four of them, corresponding to the video titles Author Playback Number of Barrages`
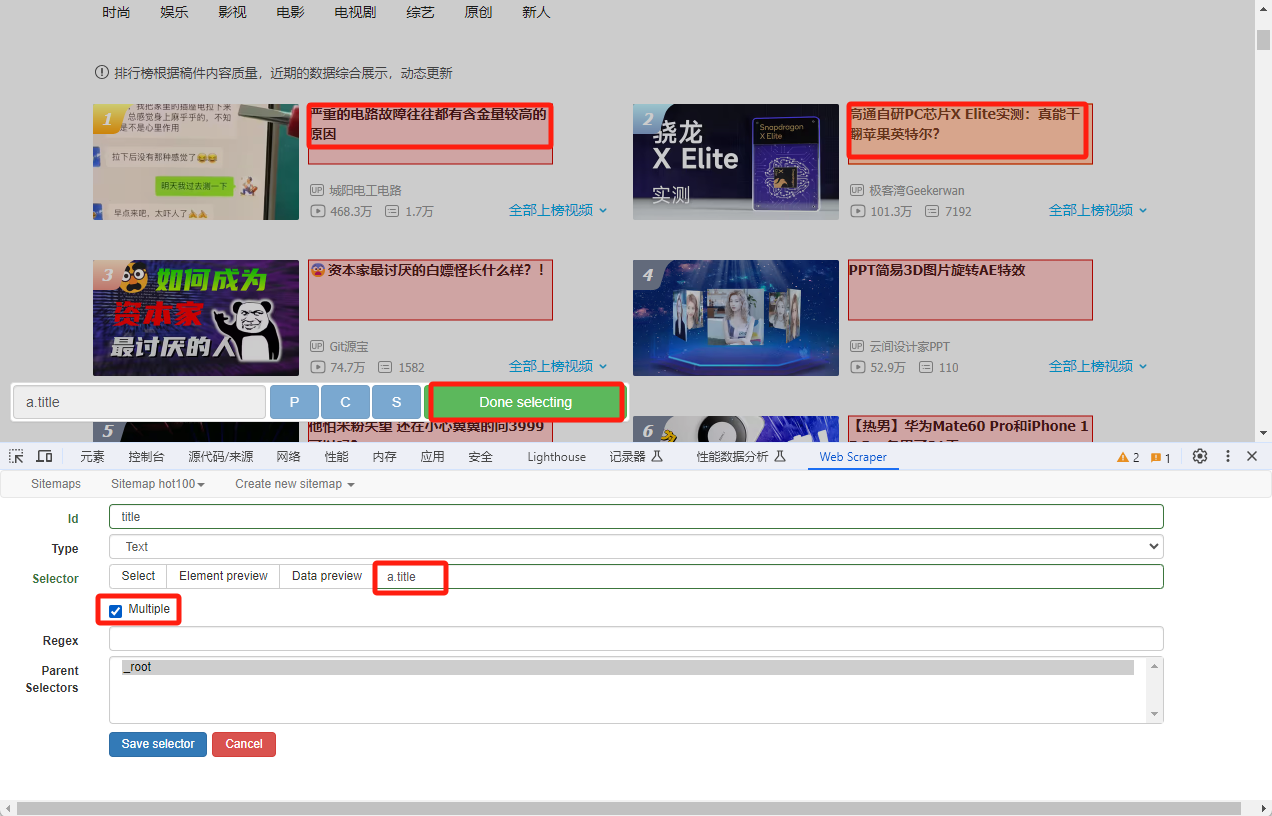
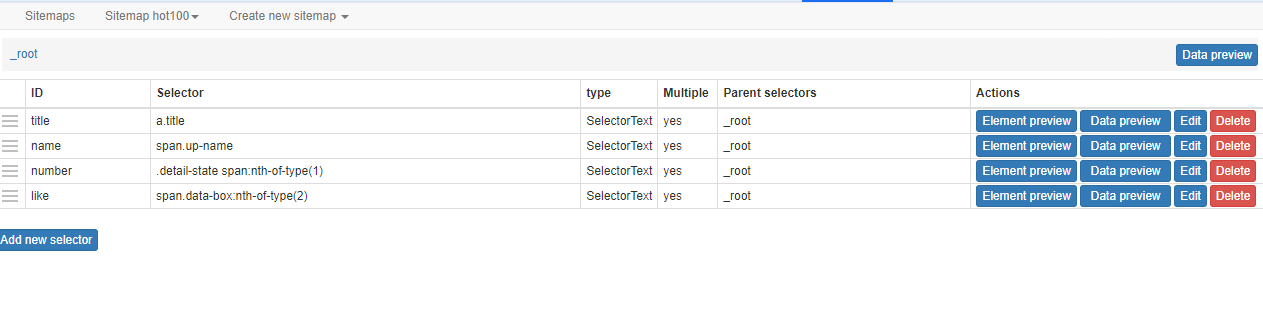
After the configuration is complete, click Scrape to start crawling.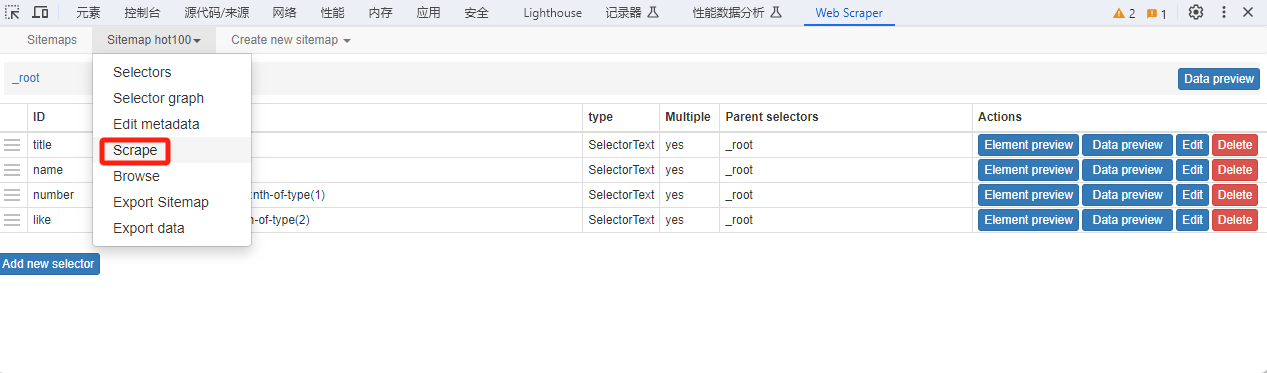
After the crawler is finished, export the results.
After exporting, the data was found to be quite messy. This is because the corresponding four fields have the same priority. How to solve this problem?
Know container
The web scraper mentions the concept of containers, which is like a div in html. Put the same div in the page into the same container. Read data from a div from the container. The specific methods are as follows:
Click Create new sitemap to create the container. Type Select Element 
Next, double-click the container to enter the container. Create the field you want to crawl again in the container.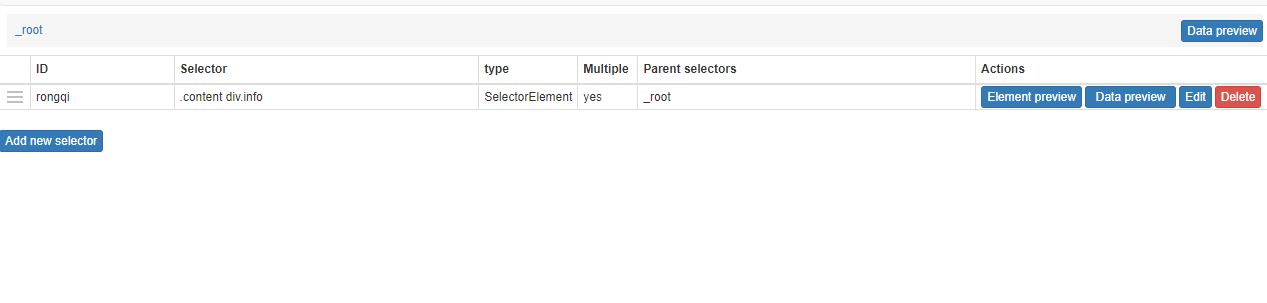
The overall structure is as follows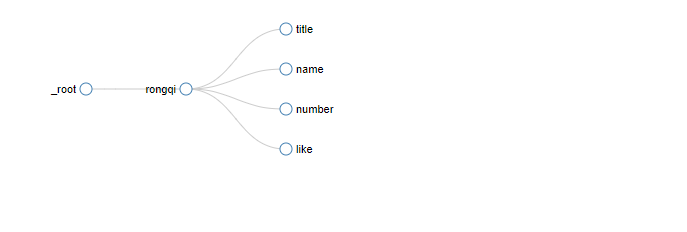
The final crawler effect.
Crawl Level 2 Page
For example, in the case of appeal, we only obtained the number of views and the number of barrage. The number of likes and favorites in the B station is not presented. Instead, it is in the secondary page.
At this time, we need to jump to the second page after crawling on the first page. The specific methods are as follows:
Enter the container and select the title field type as link. (Click on the title to enter the secondary page) 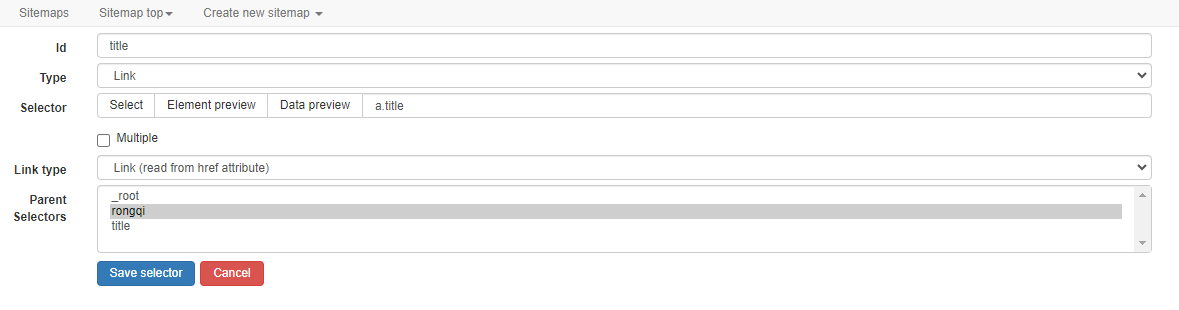
Double-click the title field to create fields that like and coin collection in this field.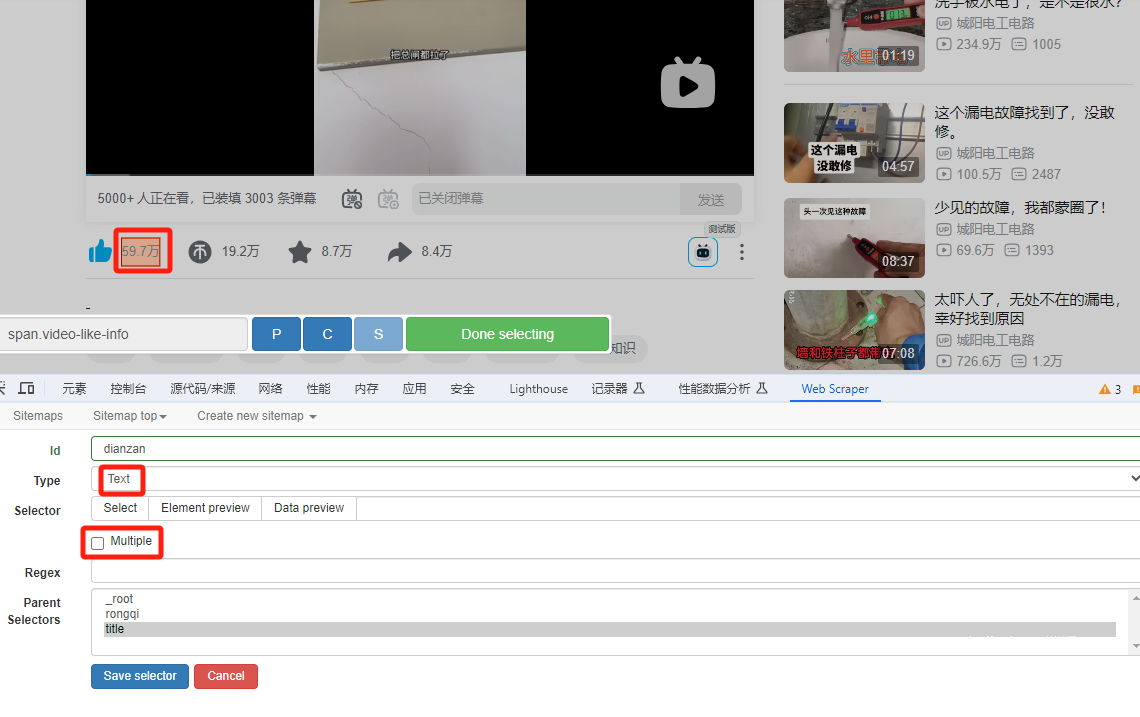
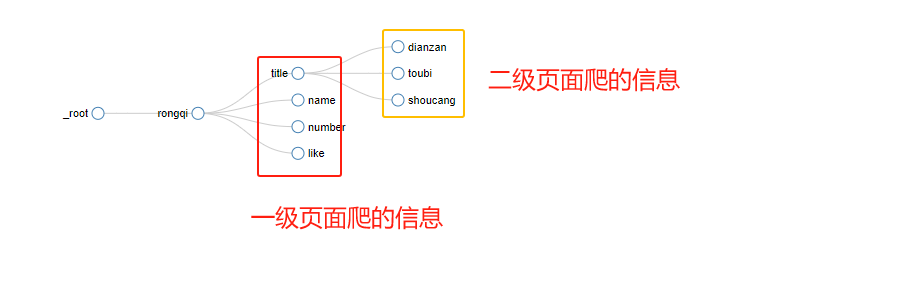
The final effect is as follows 
Crawl paging information
In practice, a lot of information is paginated. For example, we crawl all the video information of the author on B.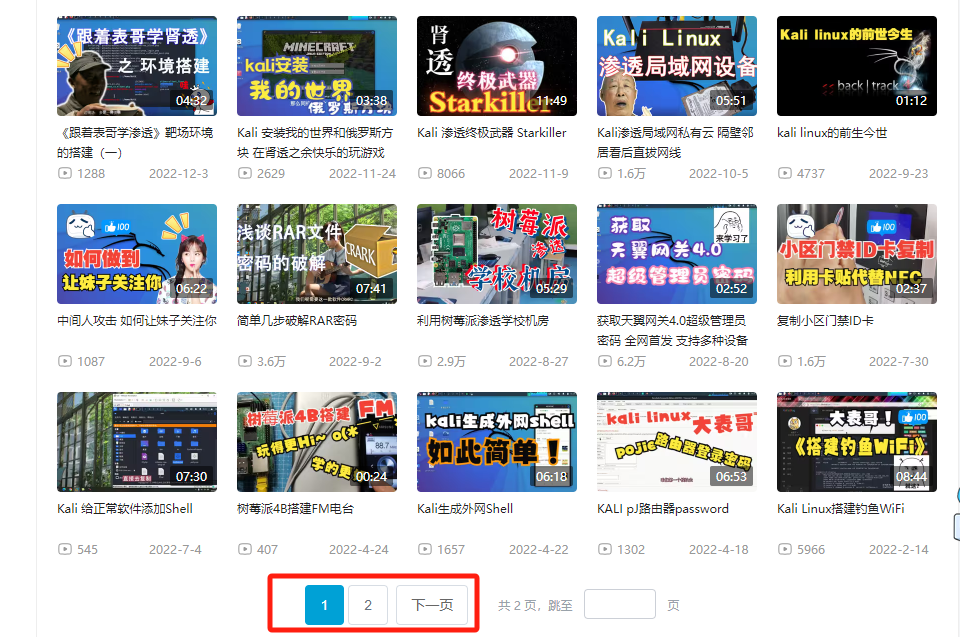
Crawl the regular next button.
In many cases, we can observe the direct change pattern of the url by clicking the button and querying the response request. like
Page 1 https://space.bilibili.com/430579369/video?tid=0pn=1keyword=order=pubdate Page 2 https://space.bilibili.com/430579369/video?tid=0pn=2keyword=order=pubdate
Through observation, it is not difficult to find that by using pn=to control the operation of the button, we just need to add the corresponding variable to it. If there are ten pages of data in total, we can set it to pn=[1-10]
Example: Crawl all videos of Xiaoyaozi Big Cousin.

No rules
For non-standard, we can use container simulation clicks to crawl.
First, we create crawlers and containers.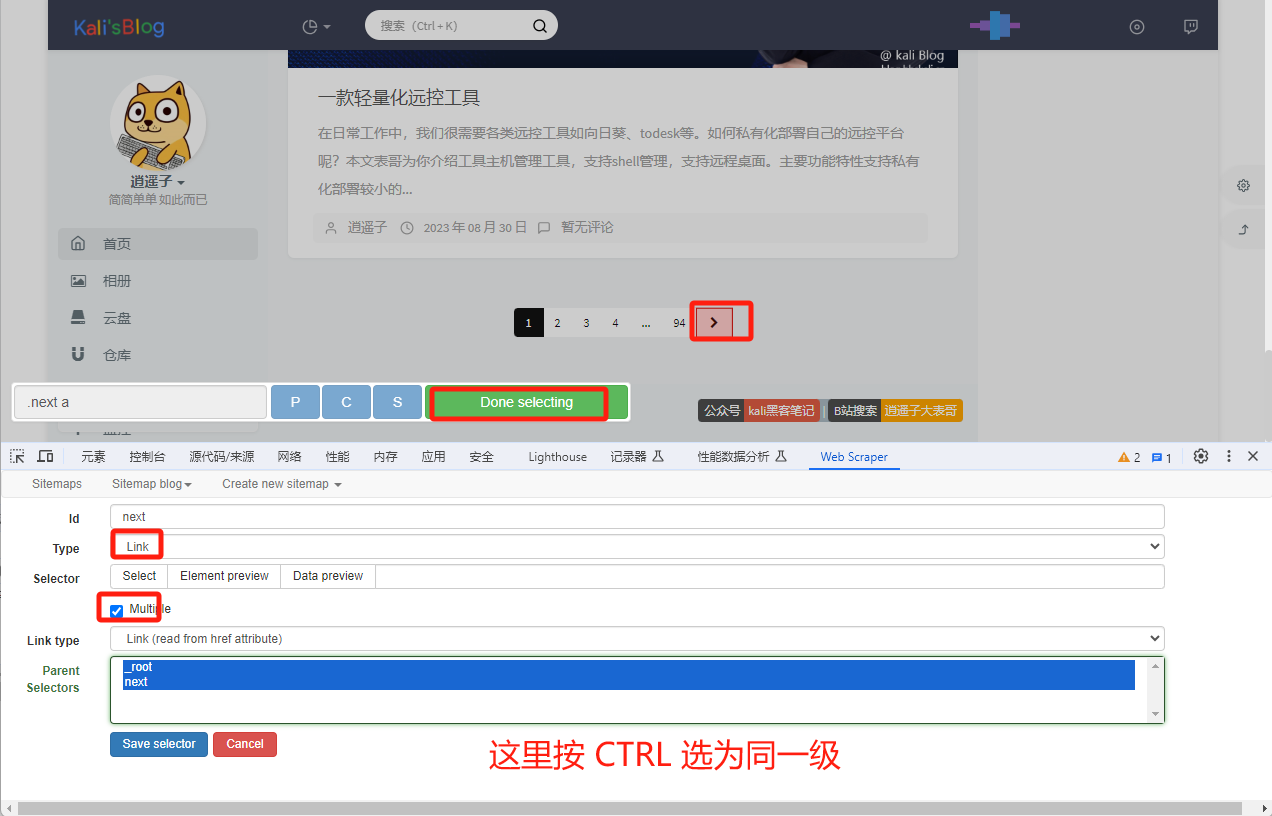
Next create the container 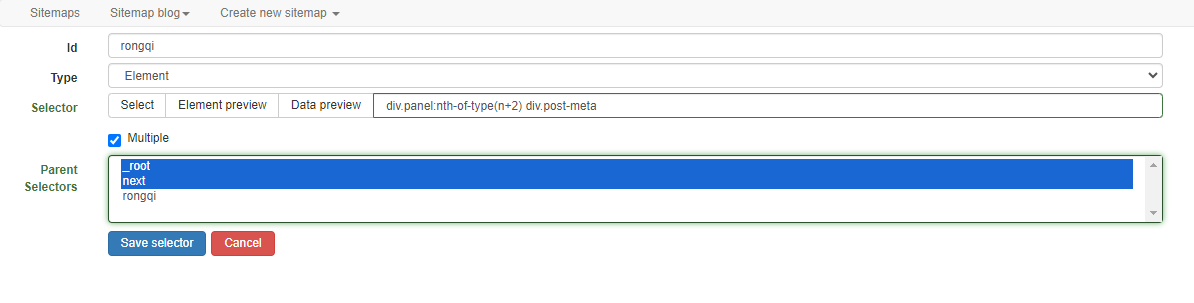
The structure is as follows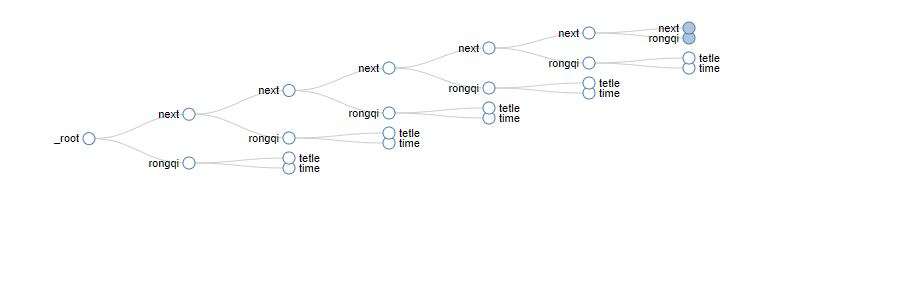
Crawling effect 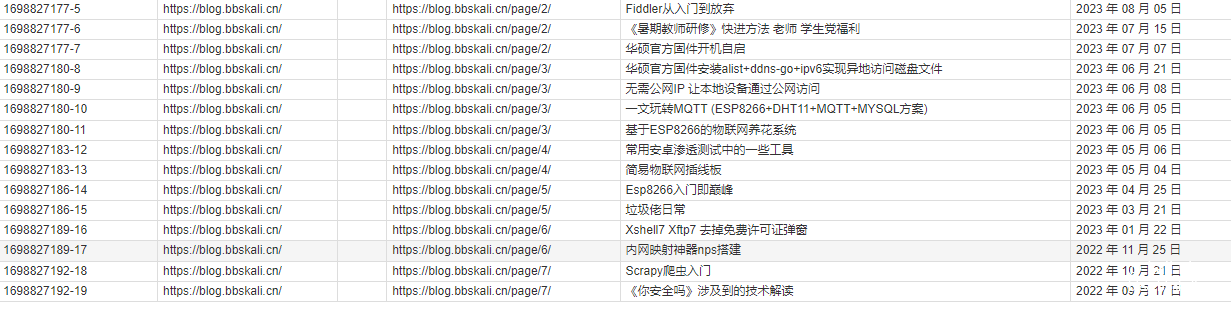
Summary
It is completely possible to use web scraper to complete some simple crawler tasks. It is relatively simple to get started, but it may not work for some sites with anti-crawler mechanisms.