.png.c9b8f3e9eda461da3c0e9ca5ff8c6888.png)
1。 MySQLデータをインポートするための予備設定
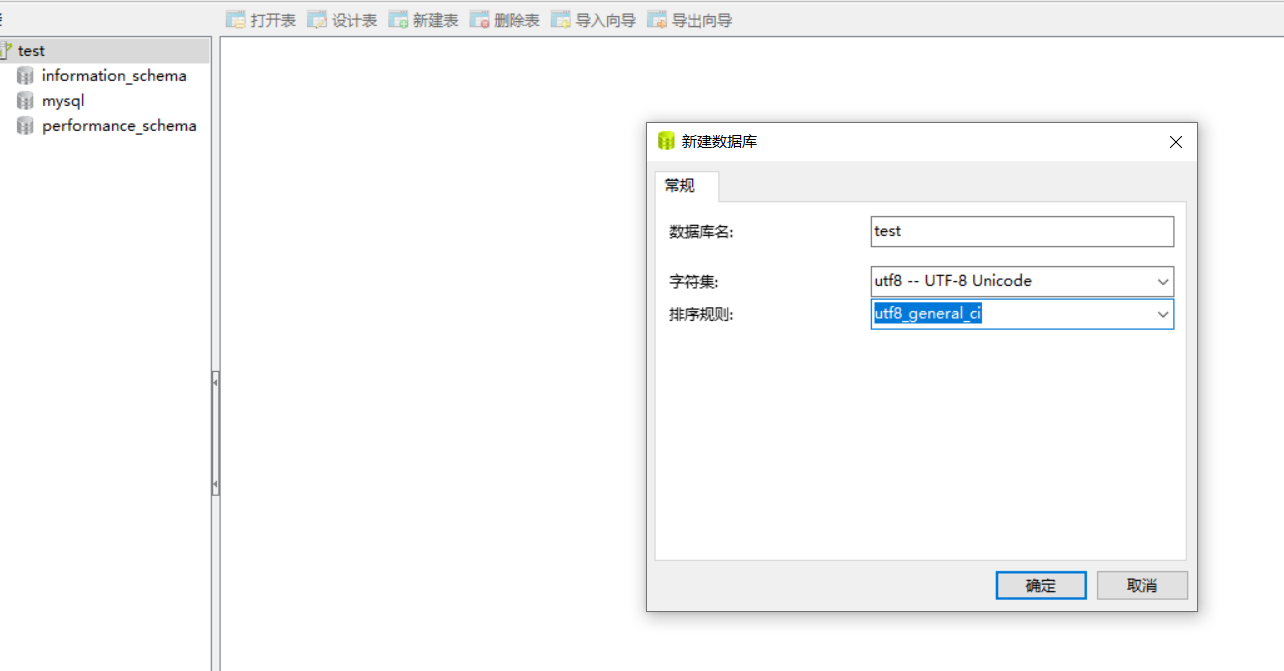
1.ライブラリとテーブルの統一エンコードをUTF8に設定し、データのエンコードに従って変更します(すべてのデータはUTF-8形式に変換できます。
2。MySQLデータベースの構成を最適化します
my.ini最適化された構成:
[mysql]
デフォルト-Character-set=utf8
[mysqld]
ポート=3306
beadir=f:/phpstudy_pro/extensions/mysql5.7.26/
datadir=f:/phpstudy_pro/extensions/mysql5.7.26/data/
Character-Set-Server=utf8 #defaultデータベースエンコーディング
Default-Storage-Engine=myisam #databaseエンジン、Myisamはクエリに適しています
max_connections=1000 #maximumクライアントとサーバー間の接続の数、デフォルトは1000です
collation-server=utf8_unicode_ci
init_connect='名前utf8'を設定
innodb_buffer_pool_size=4096m
innodb_flush_log_at_trx_commit=2#2に設定すると、このモードは0よりも高速で安全です。オペレーティングシステムがクラッシュしたり、システムの電源を切った場合、すべてのトランザクションデータが前の秒で失われる場合があります。
innodb_lock_wait_timeout=120 #defaultパラメーター:innodb_lock_wait_timeoutロック待機時間を120年代に設定します。データベースロックがこの時間を超えると、エラーが報告されます。
innodb_log_buffer_size=16m #itは16m-64MBの値をとることをお勧めし、独自のメモリは8gです。
innodb_log_file_size=256m#一般に、256mはパフォーマンスと回復速度の両方を考慮することができます。大小を問わずお勧めできません
Interactive_Timeout=120#インタラクティブ接続を閉じる前にサーバーがアクティビティを待機する秒数
join_buffer_size=16m#ジョイントクエリ操作で使用できるバッファサイズ。 100個のスレッドが接続されている場合、16m*100を占有します
key_buffer_size=512m #indexバッファー、通常は約4GBのメモリを持つサーバー用に、このパラメーターは256mまたは384mに設定できます
log_error_verbosity=2 #ERRORロギングコンテンツ
max_allowed_packet=128m #limitサーバーが受け入れたパケットサイズ、デフォルトは128mです
MAX_HEAP_TABLE_SIZE=64M#デフォルト値をセットします
myisam_max_sort_file_size=64g ## mysqlインデックスが再構築されたときに使用できる最大一時ファイルサイズを使用すると、デフォルト値は
myisam_sort_buffer_size=150m #buffer myisamテーブルが変更されたときに並べ替えるために必要
read_buffer_size=512kb #cached連続的にスキャンしたブロック。このキャッシュは、Myisamテーブルだけでなく、8Gメモリだけでなく、クロスストレージエンジンです。512kbにすることをお勧めします
read_rnd_buffer_size=4m#mysqlのランダム読み取りバッファーサイズは、終末のメッセンジャーを示唆しています
server_id=1
#SKIP外部ロックのSKIP-EXTERNAL-LOCKING=
SORT_BUFFER_SIZE=256KB #Sortingバッファー
table_open_cache=3000
thread_cache_size=16
tmp_table_size=64m
wait_timeout=120
secure-file-priv=''#任意のディレクトリにインポートできます
log-error='f:/phpstudy_pro/extensions/mysql5.7.26/data'
[クライアント]
ポート=3306
デフォルト-Character-set=utf8
2。さまざまなデータインポート方法
インポートされたデータ型は、SQLデータ、TXTテキストデータ、CVS(XLS)データ、およびアクセスおよびMSSQLデータ形式のデータです。
1.TXTテキスト形式のデータインポート
(1)。 TXTの体積は400mを超えません。それを超えると、均等に分割されます。
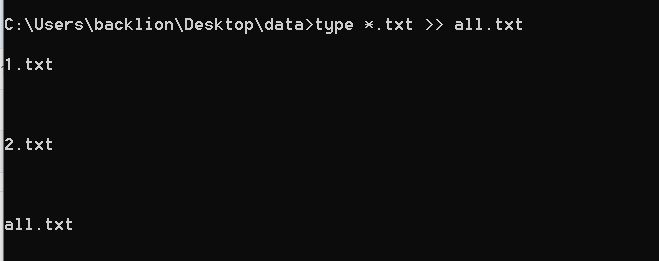
(2)複数の小さなファイルのTXTファイルとターゲットTXTSをマージする
TXTファイルをマージするコマンド:
type *.txt all.txt(windows)
 cat * 1.txt(linux)
cat * 1.txt(linux)
(3)TXTファイルのクイックインポート方法(タブ間隔分割、ENTERおよびLINE BREADYを使用)コマンド:
mysql -u root -p
テストを使用します。
データインフィル 'J:/data/weibo/weibo/weibo_1.txt' '\ r \ n'(tel、uid)で終了した「\ t」ラインで終了したweibo_info1フィールドにロードします。
注:ここでインポートされるTXTファイルパスは相対的な物理パスです。\ tは、フィールド間の分割記号がタブ(スペース)であることを意味します。
(4) Quick import method of txt file (using -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
データを浸透させる 'e:/test.txt'は、「\ r \ n」(tel、qq)で終了した「 '----」で終了したテーブルテストフィールドに終了しました。
(5)TXTファイルのクイックインポート方法(文字分離、キャリッジ、ラインブレイクを使用):
データを浸透させる 'e:/test.txt' '' \ r \ n '(tel、qq)で終了したラインで終了したテーブルテストフィールドに
(6)TXTテキストフィールドに二重引用文字を含むフィールドは、予期しない終了を引き起こします。ここでは、コマンドごとに囲まれたものを使用して、二重引用符を削除します。
load data infile 'E:/test.txt' into table test FIELDS TERMINATED BY ',' enclosed by ''' lines terminated by '\r\n' (tel,qq);
(7)負荷データのインポートパラメーターの詳細
'によって終了したフィールド、#は、フィールドデータがコンマで区切られることを意味します。
'\ n'#によって終了したフィールドは、各データのライン間のセパレーターが新しいラインシンボル(Linux)であることを示します
'\ r \ n'#によって終了した行は、各データライン間のセパレーターが新しいラインシンボル(Windows)であることを示します
''#deven \ delete \をフィールド値で削除することを意味します
'' '#フィールド値から二重引用符を削除することを意味します
(Tel、QQ)#テーブルに対応するフィールド名、これはtest.txtファイルのデータフィールド名に対応する必要があります
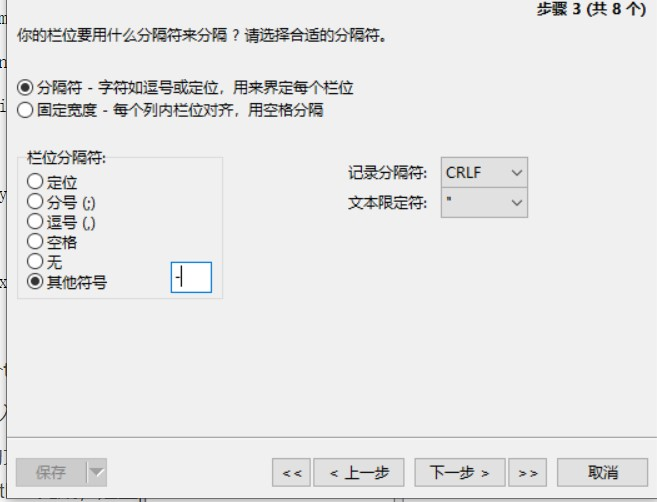
(8)小さなTXTファイル(TAB以外のレギュラースペーサー)、単純な操作NAVICATを使用してデータをインポートできます
セグメンテーションでインポートされているデータフィールドとターゲット列のデータに注意してください。
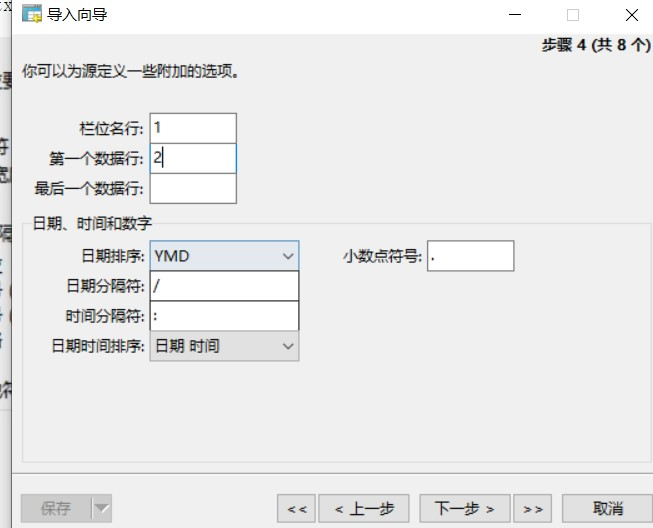
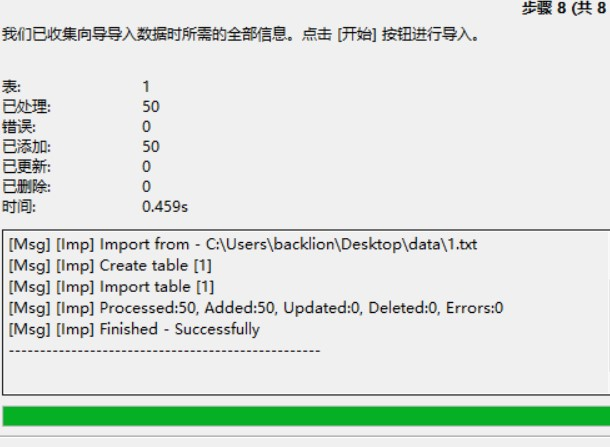
(9)複数のTXTファイルをMySQLにインポートします
インポートTXTファイルをバッチする場合は、バッチファイルを介して複数のインポートステートメントの実行を完了することができます。
SQLステートメントファイルを作成するには、複数のプログラミング言語を使用して、インポートするTXTファイルの名前を取得してSQLコマンドを作成できます。
ここでは、Pythonを使用してPythonファイルcreate_sql.py、サンプルコードを作成します。
インポートグローブ
writefile=open( 'c:/users/backlion/desktop/data/user_sql.txt'、 'w')
writefile.write( 'テストを使用; \ n'を使用)
glob.globのファイル名(r'c:/users/backlion/desktop/data/*。txt '):の場合
writefile.write( 'load data local infile' + '' '' ' + filename.replace(' \\ '、'/') +' ' +' into ' +' '' + '-----' + '' ' +' '' + '' '' '' '' '' '' '' + '\ r \ n' + ' +' '' + '' + '; \ n'
writefile.close()
このようにして、データフォルダーにインポートされるTXTファイルのすべての名前はSQLステートメントに作成され、user_sql.txtに配置されます。コンテンツはほぼ次のとおりです。
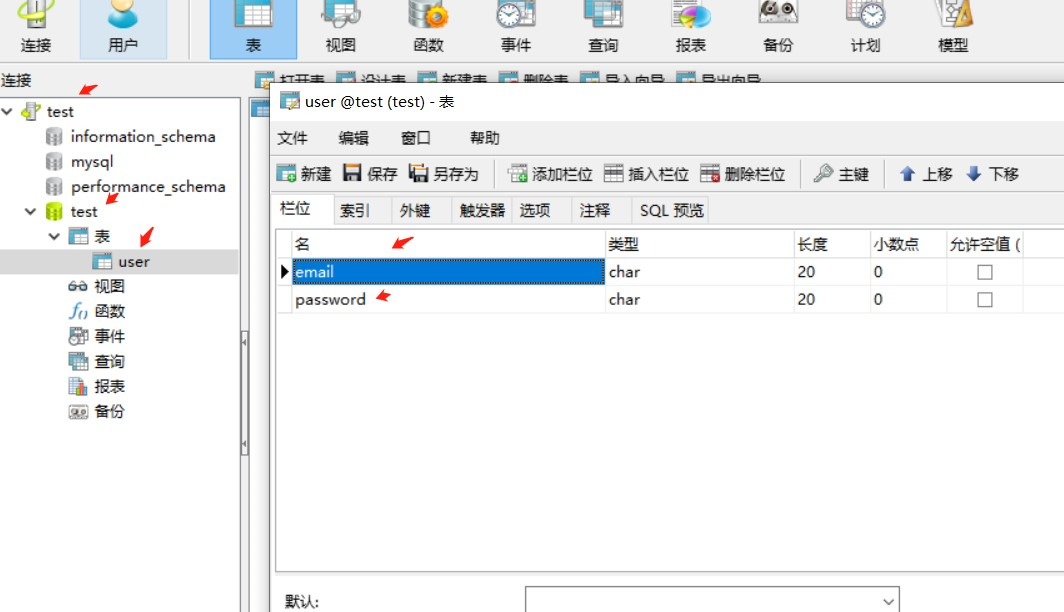
 テストとしてデータベースを作成し、テーブル名はユーザー、フィールド名は電子メールとパスワードです。
テストとしてデータベースを作成し、テーブル名はユーザー、フィールド名は電子メールとパスワードです。
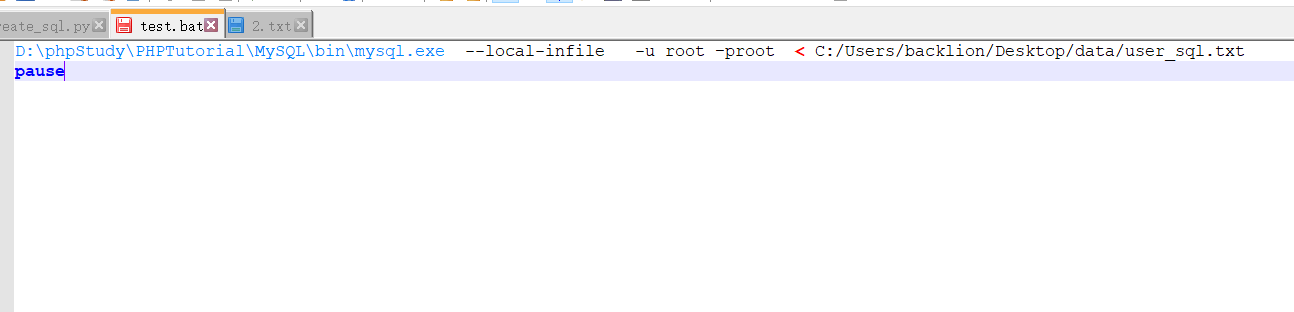
 Create .BATバッチファイル実行(1)生成されたSQLコマンドファイル
Create .BATバッチファイル実行(1)生成されたSQLコマンドファイル
d: \ phpstudy \ phptutorial \ mysql \ bin \ mysql.exe - local -infile -u root -proot c:/users/backlion/desktop/data/user_sql.txt
一時停止
2。CSVファイルをMySQLにインポートします
(1)。単一のCVSインポートMySQL、クイックコマンド
mysql -u root -p
テストを使用します。
データローカルインフィル 'c:/users/backlion/desktop/data/use1.csv' '' \ r \ n '(email、password)で終了した「\ r \ n」(電子メール、パスワード)で終了したテーブルユーザーフィールドにロードします。
(2)MySQLへの複数のCVSバッチインポート
インポートTXTファイルをバッチする場合は、バッチファイルを介して複数のインポートステートメントの実行を完了することができます。
CSVファイルは、「、」コンマをスプリッターとして使用し、二重引用符または単一の引用に囲む必要があります。
SQLステートメントファイルを作成するには、複数のプログラミング言語を使用して、インポートするTXTファイルの名前を取得してSQLコマンドを作成できます。
ここでは、pythonを使用してpythonファイルcreate_sql.py、サンプルコードを作成します:(次のデータ形式CSVファイル)
インポートグローブ
writefile=open( 'c:/users/backlion/desktop/data/user_sql.txt'、 'w')
writefile.write( 'テストを使用; \ n'を使用)
glob.globのファイル名(r'c:/users/backlion/desktop/data/*。csv '):の場合
writefile.write( 'load data local infile' + '' '' ' + filename.replace(' \\ '、'/') +' ' +'に「 + '' ' +」、' + '' ' +' '' + '' '' '' '' '' ' + r' \ r \ n ' +' + '' + '' + '; \ n'; \ n ';
writefile.close()
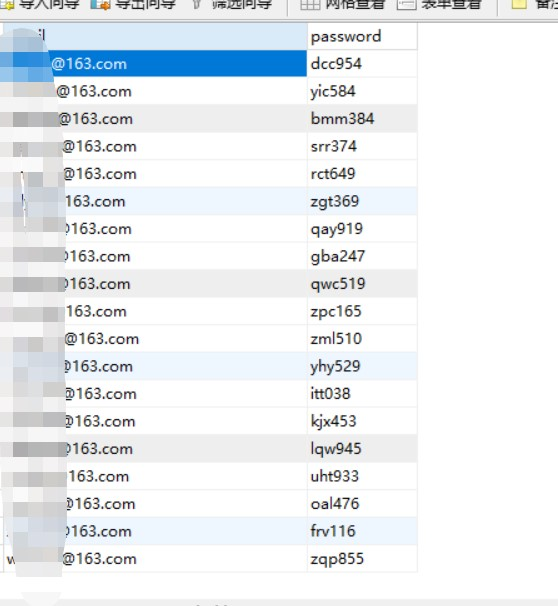
このようにして、データフォルダーにインポートされるTXTファイルのすべての名前はSQLステートメントに作成され、user_sql.txtに配置されます。コンテンツはほぼ次のとおりです。
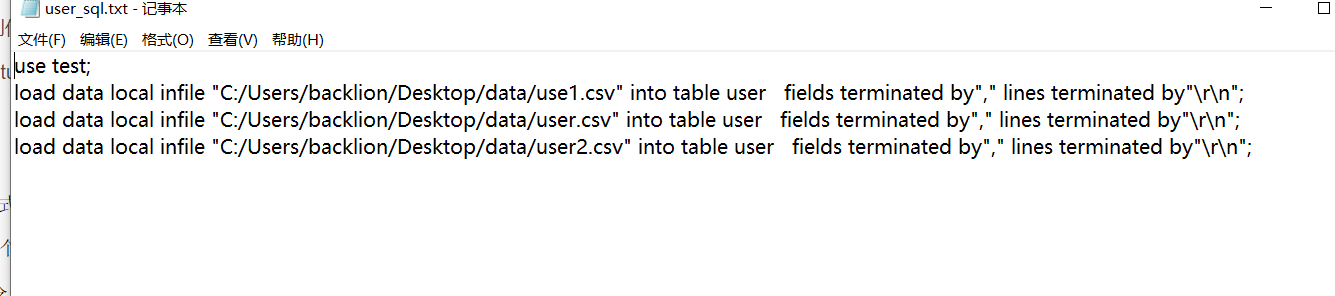 データベースの作成テストとして、テーブル名はユーザー、フィールド名は電子メールとパスワードです
データベースの作成テストとして、テーブル名はユーザー、フィールド名は電子メールとパスワードです
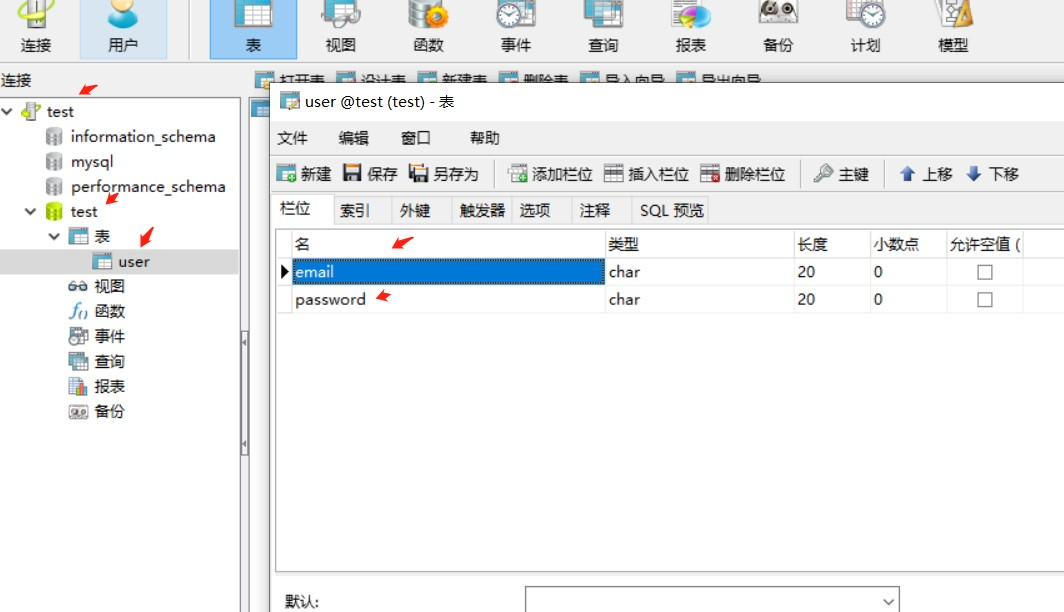 Create.BATバッチファイル実行(1)SQLコマンドファイルを生成します
Create.BATバッチファイル実行(1)SQLコマンドファイルを生成します
d: \ phpstudy \ phptutorial \ mysql \ bin \ mysql.exe - local -infile -u root -proot c:/users/backlion/desktop/data/user_sql.txt
一時停止
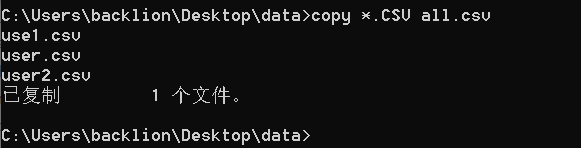
(3)複数のCSVファイルをマージします
コピー *.csv all.csv
(3)NAVICATを介してCVS形式ファイルをインポートします
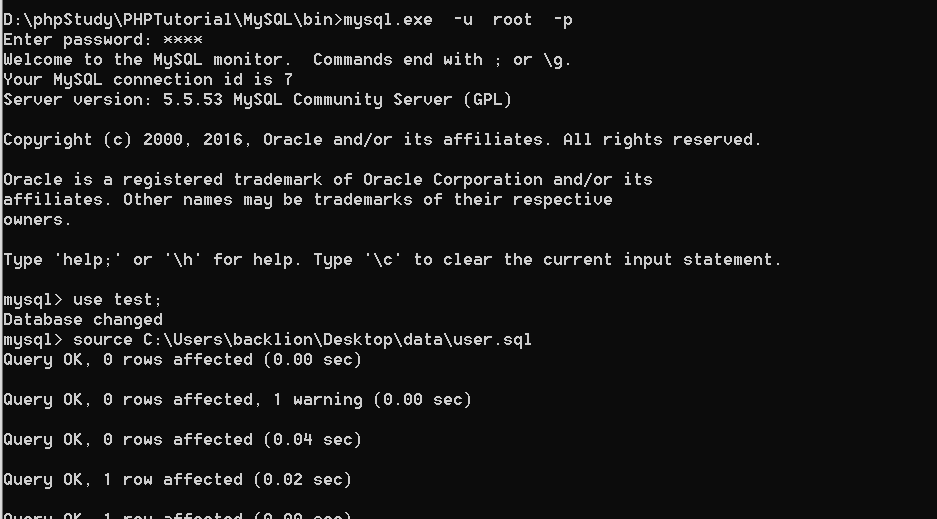
2。SQL形式でMySQLをインポートします
(1)単一のSQL形式でファイルをインポートしても、エンコードの問題を検討する必要はありません。データベースを入力した後、NAVICATを使用してデータベース属性を編集し、UTF8エンコードに変換してからインデックスを作成できます。
コマンドを使用してください:
 mysql -u root -p
mysql -u root -p
テストを使用します。
ソースD: \ test.sql;
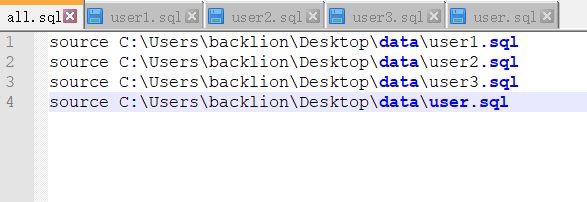
 (2)、バッチ複数のsqlファイルをインポートして新しいall.sql:vim all.sqlを作成します
(2)、バッチ複数のsqlファイルをインポートして新しいall.sql:vim all.sqlを作成します
書き込み:
ソース1.SQL
ソース2.SQL
.
ソース53.SQL
ソース54.sql
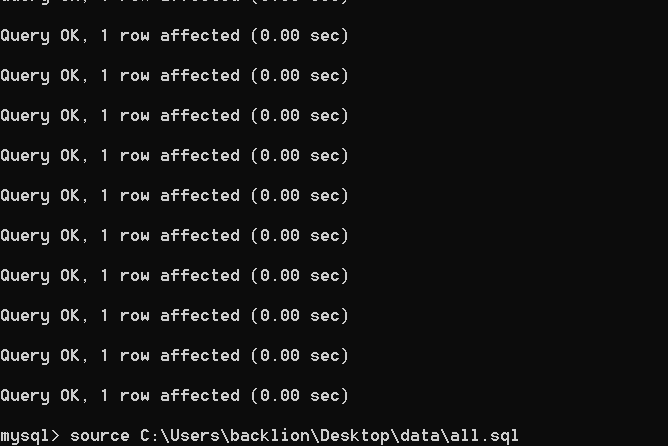
 次に実行します。
次に実行します。
mysql source all.sql
(3)複数のSQLファイルをマージします
コピー *.sql all.sql
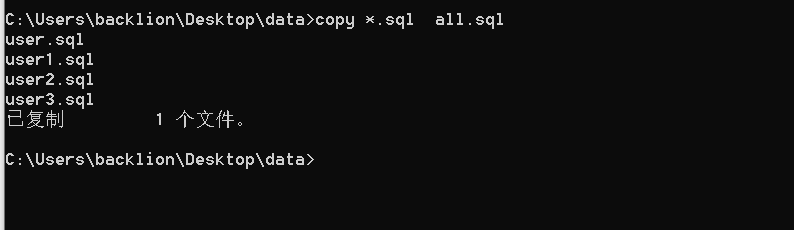
(4)NAVICATを介してSQLフォーマットファイルをインポートします
3。スキルのインポート
1。統計MySQLデータの複製の数
mysqlselect email、count(email)as count as user groupからのcount by email
mysqlcount(email)1;
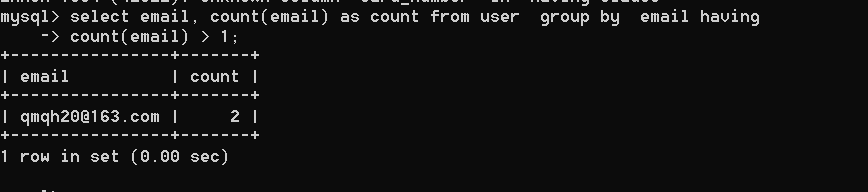
または
[ユーザーから電子メールから[ユーザー]を選択します(count(email)1を持っている電子メールでユーザーグループから電子メールを選択します);

2。データ削除
mysqlの作成テーブルtmpの選択電子メール、ユーザーグループからのパスワード、電子メール、パスワード。
または
mysqlの作成テーブルtmpユーザーグループから電子メールを電子メールで選択します。
MySQLドロップテーブルユーザー。
mysqlは、テーブルTMPの変更をユーザーに変更します。
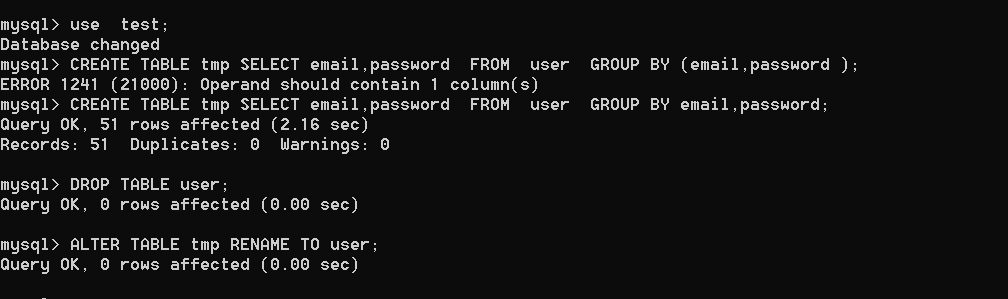 または
または
1)プライマリキー値の複製アイテムで選択したフィールドまたはレコードを選択する
新しいasを作成する(電子メール、ユーザーグループから電子メール、パスワードを電子メールで選択し、パスワードがcount(*)1);
2)インデックスを作成する(初めて実行するだけ)
new(email)でインデックスメールを作成します。
3)フィールドのレコードまたはプライマリキー値を削除して、アイテムを重複させます
where where email(newから電子メールを選択);
4)一時テーブルを削除します
新しいテーブルをドロップします。
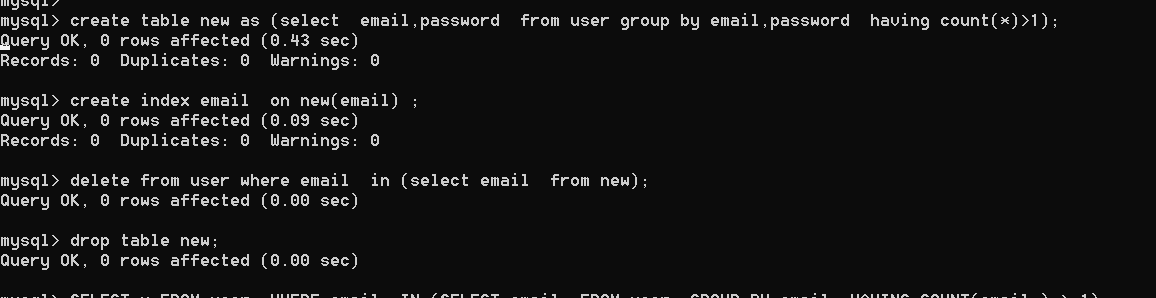
3.インデックスとクエリの最適化を追加します
一般的に使用されるクエリフィールドにインデックスを追加し、ファジークラスにBtreeストレージタイプを使用し、正確なクラスにハッシュストレージタイプを使用します。 NAVICATを使用してテーブルを選択してテーブルメッセージを開き、DDLタブを選択することをお勧めします。テーブルのSQLをはっきりと表示し、一目でインデックスがあるかどうかを確認できます。次に、データベース名を右クリックしてコンソール関数を選択して、インデックスをすばやく追加します。
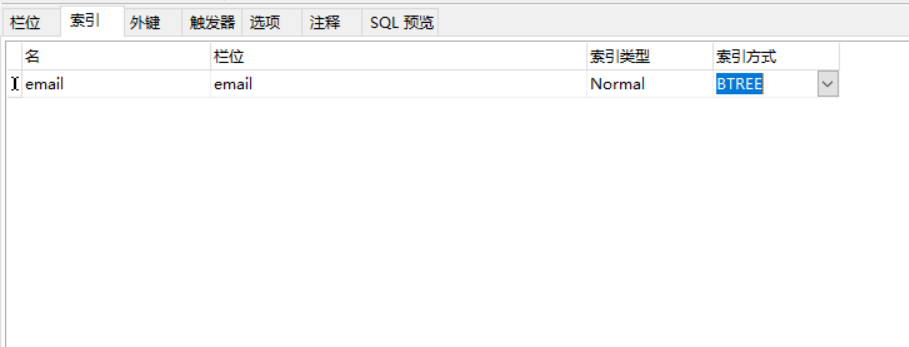 4。補足文字をサポートするために、絵文字や文字ごとに4バイトなどの特殊文字をインポートします。データベースとテーブルの文字セットをUTF8MB4に設定できます
4。補足文字をサポートするために、絵文字や文字ごとに4バイトなどの特殊文字をインポートします。データベースとテーブルの文字セットをUTF8MB4に設定できます
5。XLSおよびCVSファイルは拡大形式で、NAVICATを使用してデータベース属性を編集し、UTF8エンコードに変換してからインデックスを作成することをお勧めします。
6.最初に、NAVICATを介してデータベース、テーブル、フィールドなどのデータベース構造を作成し、インデックスを作成し、最終的にデータをインポートします(これは大量のデータを持つデータ用です。最初に大規模なデータをインポートしてからインデックスを作成すると、長い間スタックしてスタックします)
7.MSSQLをMySQLデータベースにインポートし、NAVICATインポート機能にMSSQLデータベースソースをインポートします